萬億參數大模型竟然回答不了小學數學題?最近,面對9.11和9.8哪個大的問題上,一波大模型集體翻車了。
7月17日,澎湃新聞記者實測13個主流大模型,詢問9.11和9.8的數位大小問題,其中阿裏通義千問、百度文心一言、Minimax、騰訊元寶、科大訊飛星火、智譜清言和百川智慧百小應答對,ChatGPT-4o、字節豆包、月之暗面kimi、零一萬物萬知、階躍星辰躍問、商湯商量答錯。
值得註意的是,根據媒體報道,智譜清言和百川智慧百小應也曾經「翻車」過,不過截至發稿時已經「糾正」了相關錯誤。
這波大模型的集體翻車,也引起輿論熱議,背後原因是什麽?
「通俗而言,此次很多大模型會翻車的原因是因為大模型普遍采取文本模型,容易從文本角度去理解這些數位。」長期布局AI的A股上市公司昆侖萬維CEO方漢告訴澎湃新聞記者,「如果給出明確的限定詞,告訴它們,9.8和9.11都是浮點數(實數),大模型就更容易理解這個問題的內涵。」
方漢表示,目前大模型在推理能力上確實有待最佳化,不知道人類有很多隱藏在書本外的知識很難被文本化,「大模型是對人類文本知識的壓縮,卻缺少對人類通識的壓縮。」
獵豹移動董事長兼CEO、獵戶星空董事長傅盛也向澎湃新聞記者表達了類似的觀點:「在大模型看來,數位就是字串,要回答數學問題,能力可能相對是差一些。」
「BAT隊」全答對,ChatGPT和Kimi「翻車」
值得註意的是,在記者測試的13個主流大模型中,百度、阿裏、騰訊的「BAT隊」實作全部答對。比如阿裏通義千問和百度文心一言都逐位比較9.11和9.8整數部份和小數部份的數值,得出正確答案。

阿裏通義千問

百度文心一言

騰訊元寶
不過,另一巨頭字節跳動旗下豆包大模型卻翻車了。豆包直接比較小數部份,認為「0.11大於0.80」。在第一次回答錯誤後,記者點選了字節豆包自動生成的追問,詢問是否還有其他比較方法,這次字節豆包回答正確。當記者再次追問「為什麽你兩次比較的答案不同?」時,字節豆包也再次答對,將答案更正為「9.11是小於 9.8的」。

豆包大模型
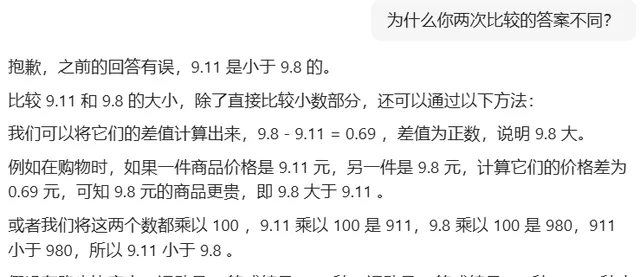
而被稱為目前最先進大模型的ChatGPT-4o亦遵循逐位比較的思路,但在比較小數點後第一位時,判斷「1大於8」,導致出錯。值得註意的是,當記者在問題中註明9.8和9.11為浮點數後,ChatGPT-4o依舊認為「0.11大於0.8」,堅持給出錯誤答案。
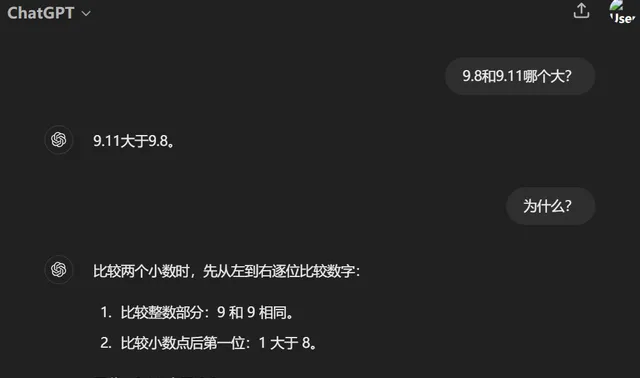
ChatGPT-4o的答案
創業公司的大模型中答案似乎五花八門,答錯的各有各的錯法。月之暗面kimi雖然也采用「從左到右逐位比較它們的數值」的思路,但在實際比較過程中認為,雖然「1小於8,但在這裏我們比較的是整個小數的值,而不是單獨的數位」。

月之暗面kimi
而零一萬物萬知則認為,因為「9.11的小數部份比9.8的小數部份更精確」,所以數值更大。階躍星辰躍問在已知9.11和9.8都是浮點數後,給出了獨樹一幟的解法,使用Python的內建函式,將這兩個數轉換為二進制表示,但最終答案仍然錯誤。
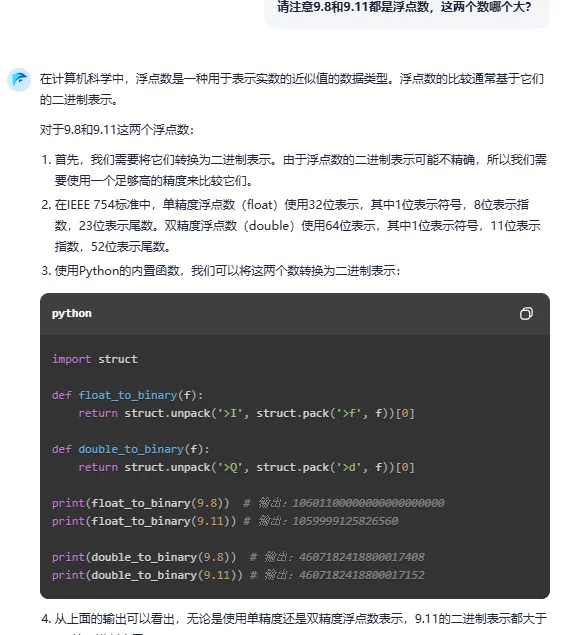
階躍星辰躍問
而在記者質疑「常識是9.8大於9.11」後,一些大模型出現了前後矛盾的情況。比如,kimi雖然改口稱「我的先前解釋確實違反了數值比較的規則」,但當記者再次詢問9.8和9.11何者更大時,kimi又堅稱9.11更大。而階躍星辰躍問的解答邏輯混亂,它承認「因為0.8大於0.11,所以9.8大於9.11」,但結論仍為「根據數學規則,9.11確實大於9.8」。
為什麽會在小學題目上翻車?
在外界眼中十分強大的大模型,為何會在小學數學題上翻車?
Kimi月之暗面向澎湃新聞記者表示,大模型目前還處於非常早期的階段,非常期待使用者在使用中能夠發現和報告更多的邊界案例(Corner Case),不管是「9.9和9.11哪個大、13.8和13.11哪個大」,還是此前的「strawberry有幾個r」,這些邊界案例的發現,有助於增加對大模型能力邊界的了解。
「但要徹底解決問題,不能僅僅依賴於逐一修復每個案例,原因在於這些情況就像自動駕駛會遇到的場景一樣是很難窮盡,要不斷增強底層基礎模型的智慧水平,不斷‘爬樓梯’,讓大模型變得更加強大和全面,能夠在各種復雜和極端情況下依然表現出色。」月之暗面表示。
科大訊飛研究員向澎湃新聞記者解釋稱,兩個數位的大小對於普通人來說是常識,但是對於大模型來說,它們並不能理解這兩個數位是什麽意思。如果明確告訴大模型兩個數位是浮點數再讓其進行比較的話,大模型了解到具體的知識背景之後再進行作答就可以正確說出大小了。
此外, 大模型采用的是token by token生成預測的方式 (Token是指文本中的最小單位,可以是單詞、子詞或字元),所以大模型把9.11會拆解成9/./11三部份,同理拆解9.9,所以在比較時會出現錯誤。
「雖然大模型在很多方面的能力都非常強悍,但在常識推理能力上還需要持續學習進步。」科大訊飛表示。
也有其他企業向記者表示了相同觀點,並表示在更強模型中不會出現此類問題,後續也會更新到現有公開版本中。
AI初創公司、面壁智慧CEO李大海向記者分析稱,對於人類而言,看到「9.9和9.11哪個大」這個問題,似乎是秒答,但背後其實進行了一定推理:首先采用了「大小」概念,認為「一個量比另一個量多就是大」;又采用了比較量值的概念,認為「兩個小數從左到右第一個數位不同的數位,數位高的就是大。」
「部份大模型之所以回答錯誤,實際上是因為模型的因果測量不足,不能有效確定不同步驟間的關系。」李大海認為,解決問題的方法可能是盡量在預訓練過程中提高模型智慧,不依賴微調提高模型效能,以避免破壞模型對未知資訊的因果辨識能力。或者設計某種方法,提高預訓練過程對因果關系的擬合程度。











