剛剛結束的蘋果WWDC可謂是萬眾矚目。
然而,蘋果只是在釋出會上提了一嘴powered by GPT4o,結果國內一些不專業的媒體直接報道成,Apple Intelligence是套殼的GPT4o,還有吃瓜群眾跑來我們昨天推文的評論區跟我們杠,真是大無語。

海外的社交媒體上同樣有大量謠傳,於是,蘋果坐不住了,官方緊急釋出了一篇網誌,正式公布了Apple Intelligence背後的基礎生成模型是——蘋果自研的模型!

官博連結:
https://machinelearning.apple.com/research/introducing-apple-foundation-models
雖然Siri確實可以直接呼叫GPT介面,但這只是僅僅是Apple Intelligence可呼叫的外部模型之一 。
根據網誌介紹,Apple Intelligence背後的基礎模型是蘋果自研的 一個約30億參數的端側語言模型(Apple On-Device) 和一個透過私有雲端運算並在 Apple 芯片伺服器上執行的 更大的基於伺服器的語言模型(Apple Server),這些模型都針對蘋果使用者的日常行為進行了微調訓練。
3.5研究測試:
hujiaoai.cn
4研究測試:
askmanyai.cn
Claude-3研究測試:
hiclaude3.com
妥妥地是為自己正名了。畢竟大模型如火如荼的一年半時間裏蘋果直接「銷聲匿跡」,這次終於悶聲幹了件大事,肯定不能被隔壁偷家了。
Apple Intelligence 背後是多個模型
Apple Intelligence由多個強大的LLM組成,針對使用者體驗進行了設計和微調,能夠執行編寫和最佳化文本摘要、確定通知優先級、為與家人和朋友的對話建立有趣的影像,以及簡化跨套用的操作等任務。
蘋果官網目前詳細介紹了其中兩個模型:其中一個參數量為3B,可以直接在手機等終端器材上執行;另一個是更大的語言模型,雖然沒有明確參數量,但其效能可以與GPT-4對標 。該模型可透過私有雲端運算獲得,並在Apple的伺服器上執行。
接下來,我們一起來看看這兩個模型的技術實作是如何完成的。
模型的訓練主要分為以上5步 ,我們一個一個看。
數據預處理和模型預訓練
基礎模型是在Apple的AXLearn框架上訓練的,這是Apple在2023年釋出的一個開源專案。AXLearn構建在JAX和XLA之上,能夠在各種訓練硬件和雲平台上高效且可延伸地訓練模型,包括TPU以及雲端和原生的GPU。此外,還結合使用了數據並列、張量並列、序列並列和完全分片數據並列(FSDP)來在數據、模型和序列長度等多個維度上擴充套件訓練。
訓練數據均來源於授權數據,包括為增強特定功能而選擇的數據,以及透過爬蟲AppleBot收集的公開數據,並刪除了私密敏感和帶有侮辱歧視字眼的數據。
模型Post-Training
Apple在官網上提到,他們使用了兩個原創的演算法用於後訓練,顯著提升了模型的指令執行效果。
(1) 使用教師委員會( teacher committee) 的拒絕采樣微調演算法(rejection sampling fine-tuning algorithm)
(2) 使用映像下降策略最佳化( mirror descent policy optimization) 和留一優勢估計(eave-one-out advantage estimator) 的來自人類反饋的強化學習 (RLHF) 演算法
模型最佳化
(1) 分組查詢註意力機制 (Grouped Query Attention, GQA):無論是器材端還是伺服器端的模型,都使用了分組查詢註意力機制。透過共享的輸入和輸出詞匯嵌入表,以減少記憶體需求和推理成本。器材端模型的詞匯量為49K,而伺服器模型的詞匯量為100K,包括額外的語言和技術詞匯。
(2) 低位元化量化 (Low-bit):在器材端推理中,采用了低位元化技術,這是實作必要的記憶體、功耗和效能要求的關鍵最佳化技術。為了保持模型質素,開發了一個新的框架,使用LoRA介面卡結合了混合的2-bit和4-bit配置策略——平均每個權重為3.5bit,以達到與未壓縮模型相同的準確性。
(3) Talaria :Talaria是一個互動式模型延遲和功耗分析工具,可以更好地指導每個操作的位元速率選擇。模型還使用了啟用量化和嵌入量化,並開發了一種方法,在神經引擎上實作高效的Key-Value(KV)緩存更新。
透過這一系列最佳化,在iPhone 15 Pro上可以實作每個提示token約0.6毫秒的首個token延遲,以及每秒生成30個token的速度。這種效能是在不使用token推測技術的情況下實作的,而使用該技術後,token生成速度將進一步提高。
模型微調
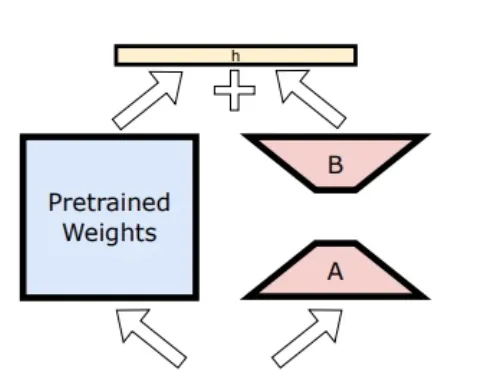
模型微調的方法是Adapter微調,即把小型神經網絡模組插入預訓練模型的各層,只訓練這些小網絡而不改變預訓練模型的參數。具體來說,對註意力矩陣、註意力投影矩陣以及點狀前饋網絡中的全連線層進行適配,從而調整Transformer架構中解碼層的合適部份。

透過僅微調介面卡層,基準預訓練模型的原始參數保持不變,從而保留了模型的通用知識,同時將介面卡層調整為支持特定任務。模型使用了16位元表示介面卡參數,對於約30億參數的器材端模型,rank 16 介面卡的參數通常只需要幾十兆字節。這些介面卡模型可以動態載入,暫時緩存於記憶體中,並進行交換——使基礎模型能夠在執行任務時動態專門化,同時高效管理記憶體並保證作業系統的響應速度。
效能表現
說了這麽多,那麽這兩個模型的效能表現到底如何呢?下面給出了6個維度的評估。3B的小模型就稱為 Apple On-Device ,伺服器上執行的大模型就稱為 Apple Server 。
人類滿意度得分
首先是評估模型的摘要生成能力,根據評分者在五個維度上的得分,摘要被分為「好」、「中」、「差」。如果所有維度都很好(越高越好),則結果被歸類為「好」。如果任何一個維度很差(越低越好),則結果被歸類為「差」。

可以看到Apple On-Device的摘要生成能力強於同類模型Phi-3-mini。
真實世界提示評估
此項評估全面考察模型能力,問題包括頭腦風暴、分類、封閉式問答、編碼、提取、數學推理、開放式問答、重寫、安全、總結和寫作等主要類別,生成的結果也由人類評估。
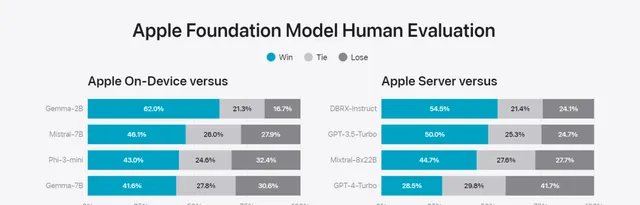
可以看到3B小模型 Apple On-Device效能強於Gemma-7B,而大模型Apple Server效能強於GPT-3.5-Turbo,略遜於GPT-4-Turbo。
輸出危害評估
此評估考察了針對有害內容、敏感話題和事實的違規回應比例(越低越好)。
可以看到,Apple On-Device和Apple Server比現有的模型都安全的多,這也符合蘋果公司一向謹慎行事的風格。

有用性評估
模型僅僅安全還不夠,這項評估考察了輸入的內容是合法內容時,人類評估者更喜歡哪個模型生成的內容。
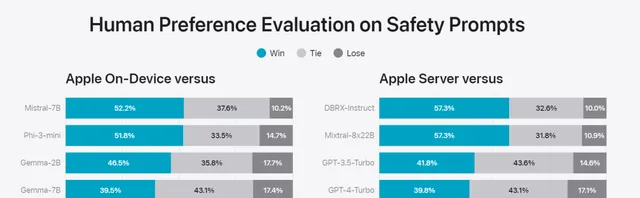
可以看到,Apple On-Device和Apple Server生成的話更受人類喜歡。
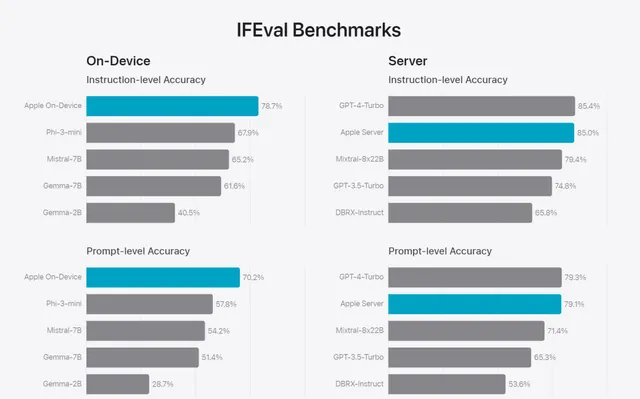
指令遵循評估 (IFEval)
這項評估測試了模型遵循人類指令的能力,可以看到兩個模型的能力都較為領先。
寫作能力評估
最後一項評估是寫作能力評估,可以看到兩個模型的能力也絲毫不落後。

Next
值得留意的是,蘋果的這些模型在預訓練之後,又利用蘋果使用者的器材行為日誌做了微調訓練&adapter訓練,這也難怪它在系統級的任務上表現這麽驚艷。
由於OpenAI根本沒有這些系統級的使用者數據,所以GPT系列模型再前進演化也很難去勝任作業系統級別的任務,從這個角度來看, 如果OpenAI始終只是蘋果系統裏的一個APP,那註定未來堪憂啊。

參考連結:
[1] https://machinelearning.apple.com/research/introducing-apple-foundation-models











