如果你是一位初级或中级的机器学习工程师或数据科学家,这篇文章非常适合你。在选定了你偏爱的机器学习库,如PyTorch或TensorFlow,并掌握了模型架构之后,便可以训练模型解决现实问题。

1. MLFlow — 实验和模型追踪
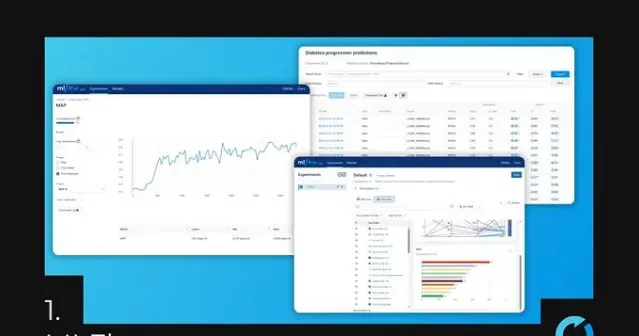
想象一下如果你是一位机器学习开发人员,正在构建一个预测客户流失模型的项目。需要使用 Jupyter 笔记本探索数据,尝试不同的算法和超参数。随着项目的进展,Jupyter笔记本变得越来越复杂,充满了代码、结果和可视化。使得追踪项目进展、识别什么内容有效内容什么无效变得愈发困难。
此时,MLflow便大显身手了。MLflow是一个平台,自始至终助力管理机器学习实验,确保可追溯性和可复制性。它提供了一个集中的存储库,用于存储代码、数据和模型组件,以及一个溯源系统,记录包括超参数、指标和输出在内的全部实验内容。
MLflow帮助你避免Jupyter笔记本使用陷阱的具体路径:
1.集中存储库:MLflow使你的代码、数据和模型工件组织有序且易于访问,可以快速找到所需的资源,避免迷失在笔记本的迷宫中。
2.实验追踪:MLflow记录每一个实验,包括使用的确切代码、数据和超参数。这使你能够轻松比较不同的实验,并识别导致最佳结果的因素。
3.可复制性:MLflow使得用相同的代码、数据和环境复制最佳模型成为可能。这对于确保实验结果的一致性和可靠性至关重要。
所以,如果想构建有效的机器学习模型,抛弃Jupyter笔记本的混乱,拥抱强大的MLflow是个不错的选择。
2. Streamlit — 小而快的Web应用程序
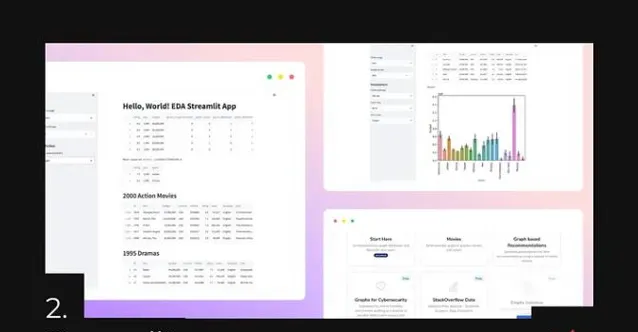
Streamlit是数据科学家最受欢迎的前端框架。它是一个开源的Python框架,允许用户快速轻松地创建交互式数据应用程序,对于那些没有Web开发基础知识的数据科学家和机器学习工程师来说特别有益。
使用Streamlit。开发者可以构建和分享引人入胜的用户界面,并在不需要深入了解前端经验或知识的情况下部署模型。该框架是免费的,并且是开源的,使得在几分钟内创建可共享的Web应用程序成为可能。
如果有一些涉及机器学习的小项目,使用Streamlit添加用户界面,有许多现成的模板,无须花费很长时间,在几分钟内便能完成前端。分享它也非常容易,它一定成为你简历中的亮点。
3.FastAPI — 轻松快速部署模型
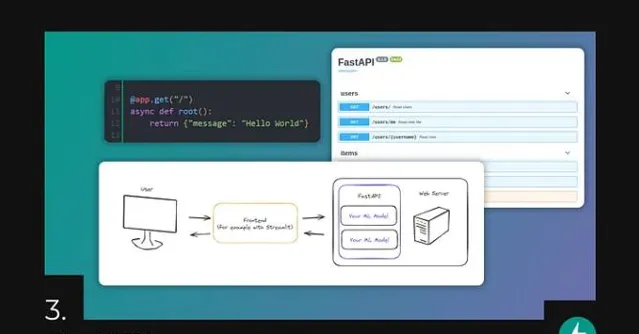
训练并验证好模型之后,需要进行部署,以便其他应用程序可以使用,这便是FastAPI的用处所在。
FastAPI是一个用于构建RESTful API的高性能Web框架,以其简单性、易用性和速度而闻名。这也是为什么它能够成为将机器学习模型部署到生产环境的理想选择。
以下是ML工程师和数据科学家应该学习FastAPI的一些原因:
速度:FastAPI非常快。它使用现代异步编程模型,能够同时高效处理多个请求,这对于部署需要处理大量数据的机器学习模型至关重要。
简单性:FastAPI易于学习和使用。它语法清晰简洁,更容易编写干净且易于维护的代码,这对于没有丰富经验Web开发人员的ML工程师和数据科学家来说非常重要。
易用性:FastAPI提供了很多功能,使得构建和部署API变得容易。例如,它内置了自动归档、数据验证和错误处理的支持,使ML工程师能够专注于他们的核心工作——构建和部署模型,节省了时间和精力。
生产就绪:FastAPI专为生产而设计,支持多后端、加密和部署工具等功能,它成为部署机器学习模型的可靠选择。
总之,FastAPI是一个功能强大且多才多艺的工具,可用于将机器学习模型部署到生产环境。它的易用性、速度和生产就绪性使其成为ML工程师和数据科学家的理想选择。
4.XGBoost — 既快又好地预测表格数据
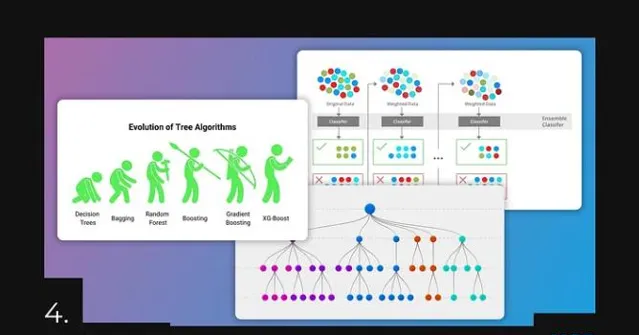
XGBoost是一种功能强大的机器学习算法,以其准确性、速度和可扩展性而闻名。它基于梯度提升框架,将多个弱学习器组合成一个强学习器。简单来说,使用多个小模型,如随机森林,将它们组合成一个大模型,最终得到一个更快的模型(与神经网络相比),但同时它是可扩展的,并且不容易 过拟合 。
以下是ML工程师和数据科学家应该学习XGBoost的一些原因:
准确性:XGBoost是最准确的机器学习算法之一,它已赢得许多机器学习竞赛,并且在各种任务中始终名列前茅。
速度:XGBoost非常快,能够快速高效地在大型数据集上进行训练和预测。这使得它成为以速度首要的应用程序(如实时欺诈检测或金融建模)的良好选择。
可扩展性:XGBoost具有高度的可扩展性。它可以处理大型数据集和复杂模型,而不牺牲准确性。这使得它成为数据量大或模型复杂性高的应用程序的最佳选择。
如果任务涉及表格数据(如根据房间数量预测房价,或根据最后一次购买/账户数据计算客户购买产品的可能性),XGBoost是你在求助于 Keras 或PyTorch的神经网络之前应该首先尝试的算法。
5. ELI5 — 使模型更易于解释和透明
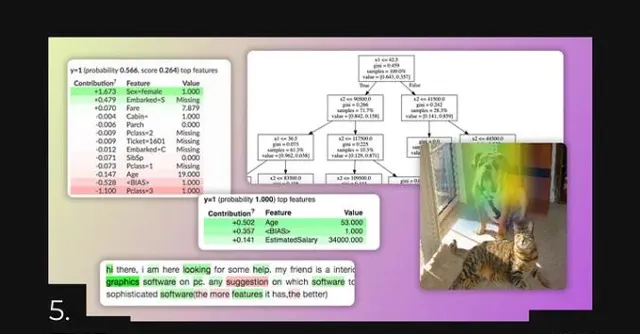
训练好模型之后,便可以部署使用它,此时模型更像是一个「黑箱」——输入内容,得到输出。模型究竟是如何工作的?没人知道。这儿是数字,那儿也是数字,最后得出了一个答案。
如果客户/老板问你,模型是如何得出某个特定答案的?你根本无法知道,你甚至不可能知道,在训练过程中哪些参数最重要,哪些只是增加了噪声?
所有这些问题都可以使用ELI5来回答。这个库将使模型变得透明、可解释和更容易理解。能得到模型、数据、训练过程、权重分布和输入参数等更多信息。除此之外,可以「调试」模型,并获得更多关于什么架构会更好工作,以及当前模型存在什么问题的见解。
ELI5支持像Scikit-Learn、Keras、XGBoost等许多库。模型可以实现图像、文本和表格数据的分类。
结论
我们探索了五个领先的数据科学框架,如果你掌握了这些库,你将获得多重优势:
1.与其他数据科学家相比,你将有更多的机会获得工作,因为你在机器学习的各个方面都获得了多项技能。
2.你将能够从事全栈项目,因为你不仅可以开发模型,还可以使用FastAPI后端部署它,并让用户通过Streamlit前端与之交互。
3.你不会迷失在「Jupyter笔记本地狱」中,因为全部机器学习实验都将通过MLFlow变得可追溯和可复制,并且所有模型都将被正确版本化。
4.对于你来说,表格数据不是问题,因为你知道如何使用XGBoost训练可扩展、快速和准确的模型。
5.大多数模型对你来说不再是「黑箱」,因为你可以通过ELI5更深入地理解它们,调试它们的思维过程并解释它们的预测。
所有这些库都将使你的生活更轻松,为你的弹药库添加许多有用且重要的技能。愉快编码!











