每經記者:李孟林 每經編輯:蘭素英
當地時間4月23日,微軟推出了開源輕量級AI模型Phi-3系列,宣稱這是目前市面上效能最強、最具性價比的「小語言模型」。
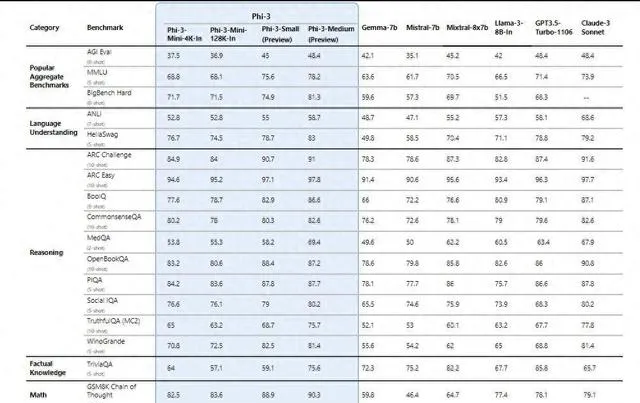
該系列的最小版本Phi-3-mini雖然參數規模僅有38億,但卻展現了超越參數規模大一倍多的模型的效能,在多項基準測試中比Meta的Llama 3 8B更優異,而Phi-3-small和Phi-3-medium這兩個版本甚至可以超越GPT-3.5 Turbo。
更令人矚目的是,Phi-3-mini對記憶體的占用極少,可在iPhone 14搭載的A16 Bionic芯片上實作每秒12個token的生成速度,這意味著 這款模型不用聯網,可以直接在手機上執行。 不僅如此,據透露,Phi-3的成本或只有同等效能模型的十分之一。
這樣的模型對於網絡資源受限或需要離線推理的場景來說,無疑是一大好訊息。據微軟介紹,印度企業已經開始用Phi-3模型來幫助資源緊缺的農民解決生產生活問題。但Phi-3系列並非沒有缺點,其在事實性知識方面的表現並不理想,不過微軟已經找到了相應的緩解之道。
手機上能跑的GPT-3.5級別模型
當地時間4月23日,微軟推出了開源輕量級AI模型Phi-3-mini,這是其Phi家族的第4代模型。Phi-3-mini是Phi-3系列中最小的,參數只有38億,未來幾周內,微軟還將推出該系列的另外兩個版本Phi-3-small(70億參數)和Phi-3-medium(140億參數)。
「 Phi-3模型是現有功能最強大、最具性價比的小語言模型(SLM),在各種語言、推理、編碼和數學基準測試中,其效能優於相同大小和規模大一級的模型。 」微軟方面表示。
具體來看,Phi-3-mini采用了transformer架構,支持4K和128K上下文視窗,也是同類小模型中第一個支持128K的開源產品。
效能上,Phi-3-mini在多項基準測試中超過了參數規模大一倍多的Llama 3 8B(80億參數),而Phi-3-small和Phi-3-medium超過了很多尺寸大得多的模型,如GPT-3.5 Turbo,而後者的參數規模高達1750億。
圖片來源:微軟
由於Phi-3-mini對記憶體的占用極少,經過壓縮後總體積可以大幅縮減至1.8GB,可在iPhone 14搭載的A16 Bionic芯片上實作每秒12個token的生成速度,意味著 這款模型不用聯網,可以直接在手機上執行。
Phi-3系列的驚艷表現來自於其訓練方式。微軟生成式AI研究院(GenAI Resaerch)副總裁Sébastien Bubeck表示,微軟在開發Phi-3時力圖確保輸入的是高質素數據訓練集。
微軟技術報告顯示,開發人員開發Phi-3時使用了3.3T tokens數據集,包括經過嚴格質素篩選的網絡公開文件、精選的高質素教育數據和編程程式碼。此外,還有AI自己生成的「合成數據」,如數學、編碼、常識推理、世界常識、心理科學等。高質素數據,再輔以獨特的指令微調和RLHF訓練,大幅提高了小語言模型的效能。
當然,Phi-3系列也有其缺點,這主要體現在事實性知識上,在相關的基準測試如TriviaQA上的表現就不如人意。不過,開發語言模型是效能和尺寸的平衡。微軟透露, Phi-3模型本身參數中沒能力儲存太多事實和知識 , 這一缺點的緩解方式是聯網接入搜尋引擎增強。
可離線使用,成本只有類似效能模型的十分之一
傳統觀點認為,大語言模型的關鍵點就在於「大」,參數越大,訓練數據體積越大,效能就更強。微軟推出輕量級的小語言模型,用意何在呢?
據微軟自己的說法, 像Phi-3這樣的小語言模型特別適合以下場景:網絡資源受限,需要在終端器材上推理或者離線推理的場景;需要避免延遲,快速響應至關重要的場景;成本受限的場景,特別是那些較為簡單的任務。
Phi-3能夠在手機上離線執行,成本大幅降低,從而大大降低了AI的實際使用門檻。
微軟高管Eric Boyd就表示,企業客戶經常發現像Phi-3這樣的小模型更適合他們的客製應用程式,因為企業的內部數據集本來就規模不大,而且 小模型需要的算力更少,成本也更為便宜。
「 Phi-3的價格不是稍微便宜一點,而是便宜得多,與具有類似功能的其他型號相比,成本差異可能是10倍的範圍 ,」微軟的Sébastien Bubeck對路透社表示。
微軟已經在探索如何在資源有限的情況下套用Phi-3。據其介紹,總部位於印度的商業集團ITC,正在與微軟合作將Phi-3用於農業領域,共同開發面向農民的應用程式Krishi Mitra,這一程式的覆蓋範圍達100萬農民。
據悉,農民可以用當地語言向Krishi Mitra提問,該應用程式會立即以使用者的本地語言提供詳細的個人化響應,幫助他們解決農作物管理、病蟲害控制、土壤健康、水資源保護、天氣預報、市場聯系和政府計劃等相關問題。
每日經濟新聞











