過去的人工智能技術,在進行自然語言處理的時候,只能理解字面的意思。為了訓練出中國人自己的大語言模型,科學家「餵」給它論文和科技文獻,讓它進行學習,從「助手」變為「助研」…
出品:格致論道講壇
以下內容為科大訊飛AI研究院副院長李鑫
演講實錄:
大家好,我是來自科大訊飛AI研究院的李鑫,今天演講的題目叫【最後一個需要人來解決的問題】。
我想可能很多人都能猜到,這是一個關於人工智能的話題。我們往往會把人工智能發展史分為3個台階,一個叫計算智能,一個叫感知智能,第三個叫認知智能。
很顯然在計算智能時代,電腦已經完全碾壓人類了,無論是運算速度還是儲存容量都比人要強大很多。到了感知智能時代,我們會提到智能語音、影像處理技術,經常說要「讓機器能聽會說」。那麽感知智能現在發展得怎麽樣了呢?我想給大家舉幾個例子。
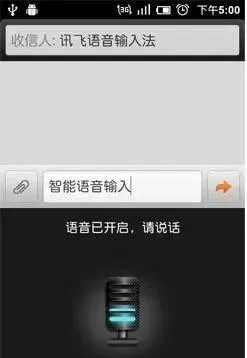
我們先來看看讓機器「能聽」,這指的是語音辨識技術。
輸入一段語音,它就能夠輸出相應的文字,相當於讓機器長了耳朵。這張圖上是2010年我們釋出的訊飛輸入法。現在語音輸入已經是件稀松平常的事了,但在那個時候,把語音輸入即時變成文字還是件稀罕事,給我們的生活工作提供了非常大的便利。
現在這個技術發展成什麽樣了呢?我們來看這個影片。影片裏的外國人說的是他們國家的語言,他的話透過語音辨識技術轉換成了英文字幕,再轉譯成我們能聽得懂的中文。
現在的語音辨識技術不僅僅能套用在安靜的、像大會一樣的場景下,還在往更復雜的場景延伸。比如在一些公共的場合裏有很多噪音,某些居家的場景下有很多回響,還有一些很復雜的環境像可能有「雞尾酒效應」的酒吧等等,這些幹擾都在逐漸地被語音辨識技術研究者攻克。
說完了「能聽」,我們再來看看這個「會說」。機器的「會說」指的是語音合成技術,它實際上是語音辨識技術的一個逆過程。
辨識是語音生成文字,而合成是文字生成語音。
這是我請來的一位神秘的嘉賓,大家能聽出來他是誰嗎?特別熱愛學習的同學能猜出來,他是「得到」的創始人羅振宇先生。這個聲音是合成的,並不是他本人說的。
這樣的合成技術並不是明星或者流量IP的專利。現在我們普通人說幾分鐘的話,就可以基於說話人的聲音提取出聲紋,生成你說任何語言的聲音。
對於一些經常出差的人來講,雖然人出差了,但完全可以用自己的聲紋在家裏給小朋友講故事、讀繪本。這是語音合成技術的一個套用,只聞其聲、不見其人。
現在我請我們的虛擬人同事「小姿」和大家打個招呼。剛才是只聞其聲、不見其人,現在是既聞其聲、也見其人。不僅聲音可以變得非常鮮活,形象也可以惟妙惟肖。它的唇型是由聲音來驅動的,說出什麽樣的聲音,就會形成什麽樣的唇形,和真人是一樣的。
「能聽」和「會說」構成了我們的語音辨識和語音合成技術,在這些技術的背後,互聯網起著非常重要的作用。
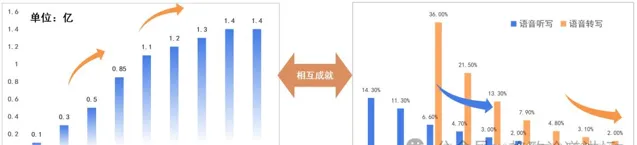
▲左:訊飛輸入法月活數據逐步上升
右:科大訊飛語音辨識錯誤率每年相對下降30%以上
我們有一個名詞叫「漣漪效應」,
它指的是當我們的使用者數上升時,使用者貢獻的數據量也會增多,技術的水平也會隨之逐漸地提升。所以當我們訊飛輸入法的月活使用者逐漸增多的時候,語音辨識的錯誤率每年會相對下降30%左右。
這就是我們說的,數據越多,模型叠代得越好;模型叠代得越好,
就會有越來越多的人願意去使用我們的產品;而使用者增多又會產生更多的數據
,這樣就會形成一個正向的良性迴圈。
如果沒有互聯網,這些鮮活的數據是沒有辦法反饋回來的,模型的叠代也會非常地緩慢,這就是互聯網讓人工智能技術進步的一個最大、最重要的作用。
怎麽理解中文的博大精深?
說完了「能聽會說」,我們自然而然就要邁到第三個台階,認知智能。但是,認知智能在做自然語言處理時會出現很多的問題
,我們給大家舉幾個例子。

比如「冬天能穿多少穿多少,夏天能穿多少穿多少」。僅僅是季節不同,其他文字沒有發生任何的變化,但是前半句和後半句的語意完全不同。前面是讓我們要盡可能保暖,後面是讓我們盡可能清涼。
再舉個例子,「校長說身上除了校徽別別別的」。我今天上場的時候,組織方給我這貼了「格致論道」的標識,除了這個標識之外,別別別的。這裏的「別別別」看起來是同一個字,但是語意完全不同。第一個「別」是不要的意思;第二個「別」是佩戴的意思,是個動詞;第三個「別」是代詞,指代其他的東西。所以如何讓電腦理解「別別別」的這種一詞多義也是我們做認知智能時一個非常重要的挑戰。
再比如說,我們的中文和英文之間還有一個很大的不同點。英文的詞和詞之間是有空格的,中文沒有。所以怎麽樣去切詞也是處理中文的一項很重要的挑戰。

這個橫幅正常的讀法是「三餐二樓歡迎新老師生/前來就餐」。但如果斷句不當,就會鬧出笑話,斷成「三餐二樓歡迎新老師/生前來就餐」。中華文字的博大精深,實際上很難被AI完全掌握。AI面對中文,有點兒捉襟見肘。

之所以會這樣,一個很重要的原因就是我們看到的僅僅是文字,但是文字底下蘊含的這些知識、常識和邏輯才是我們理解文字的重要基礎。
如果我們無法感知夏天和冬天的變化,沒有這種常識,就沒有辦法理解什麽叫做「能穿多少穿多少」。如果我們不知道什麽叫做一詞多義,沒有這種知識,就沒有辦法理解什麽叫做「別別別的」。
所以,讓機器「能聽會說」的下一個台階就是「能理解、會思考」
,語言是非常重要的一個核心。
2010年我碩博連讀時,就一直在做自然語言處理的工作。今天互聯網上正在發生「百模大戰」,「模」指的就是各家的大語言大模型。那在當時恰逢百「團」大戰,
百「團」大戰就是指很多團購網站在一起去競爭。這面的一個核心技術叫推薦系統,就是你喜歡什麽,我就給你推薦什麽,這會使電商有很高的營單量。

我當時做的事情就是分析大眾點評和美國的Yelp網站上面的使用者評論數據,從而給使用者推薦適合他們喜好的東西,比如一些合適的餐館或者菜品,以及他們可能會認識的人或者喜歡的人。這些也都要基於使用者的文本來進行挖掘,所以一直在做語言文字相關的工作。

恰好科大訊飛在2014年提出說要讓語言和語音成為機器認知革命的入口,還釋出了訊飛超腦計劃,也就是要做自然語音處理。正是在那次的釋出會上,他們提出來「要讓機器能理解、會思考」。
我覺得這些和我的方向還是挺接近的,所以在2015年博士畢業後,我就順理成章地加入了訊飛,繼續從事相關的研究工作。
90分和88分的作文區別在哪?
我進入到訊飛之後,做的第一件事就是作文批改。這個需求是很自然的。
以前讀書的時候,老師布置一篇作文很簡單,就是把一個題目給大家,每個同學寫500-800字的文章交給老師。但是,批改作文要比布置作文痛苦得多,因為每個學生的文章都得看。所以那時候,老師能畫幾個波浪線,我們就覺得心滿意足了。
但是,幾個波浪線並不能幫助我提升寫作水平,因為我不知道怎麽樣寫才能寫得更好,老師沒有做詳細的評語,因為如果所有同學的作文都讓老師批改的話,老師的工作量也很大。
於是我們就想,有沒有可能可以用人工智能技術裏自然語言處理的方式來減輕老師的工作量,還能讓學生在寫作上有更好的提升呢?

所以我們第一個任務就是作文批改,這項任務的第一個工作就是得分預測。這篇文章如果是100分制的,我們大概能給這個文章打多少分。
這個問題相對比較簡單,因為在長時間的教學過程中,老師們已經總結出了很多給作文評分的緯度,比如詞匯量、優美的語句等等。我們完全可以根據這些教學中的方式方法,從文本裏提取這些特征,然後把這些特征和最後得分做一個對映。
用人工智能技術來做得分預測的問題很快就迎刃而解了。但是這個問題解決之後,還沒有滿足老師們的需求。他們特別期待地說,這個文章得了94分,為什麽?你能不能展開說說?
這就比較困難了。展開說說就意味著你要解釋寫得好的地方好在哪兒?寫得差的地變異數在哪兒?怎麽改進?
這個問題其實一直困擾著我們,主要的難點其實有兩個。
首先,評分實際上是一個很模糊的感覺。雖然它有個定量的結果,但是90分、88分之間的差別到底有多少呢?人們對於這種數碼的感知是有一個誤差的冗余感的。但是當需要你說出來一篇文章好在哪兒、差在哪兒的時候,每個人的價值觀和價值取向是不同的。這就造成這個產品和技術做出來的時候,不同人對它的效果做的評估是不同的。
第二點,我們當時的人工智能技術只能做很淺顯的自然語言處理,除了理解字面意思之外,頂多還能再往下理解一層含義。而這些句子更深的內涵很少能被理解。要想給它一個合適的評語,我們就必須要準備評語樣版庫,用這種庫來配合自然語言處理技術。
但是隨著產品的發展,很多人不滿足於看這些套路的東西,大家希望看到一些更真誠的評語,而不是簡單的套路。因此這個產品和技術就得不到客戶的認可,一直停滯不前,直到2022年,ChatGPT的推出。
大模型背後的秘密其實很簡單
在2022年11月30日,美國Open AI公司釋出了ChatGPT,到今天我們國家其實也推出了很多自主可控的大模型。我想現在很多人都在使用類似的產品,這種大模型技術確實在顛覆認知,在我們工作生活的各個方面都扮演了非常重要的角色。

到底什麽是GPT?其實GPT很簡單,用Open AI公司CEO山姆·奧爾特曼的一句話來講,它就是在預測下一個單詞,predict next-token。

我這裏給幾個例子。比如問日本的首都是什麽?我們讓大家預測的是東京這個單詞。中國的首都是什麽?我們讓大家預測的是北京這個單詞。
如果我把日本和中國兩個字蓋住,僅僅問大家首都是什麽的時候,不同國家的人的回答就是不同的了。預測和預測的準確率實際上依賴於我們前面到底提了什麽樣的問題,或者到底往前看了多少個單詞。
如果我把中國這兩個字放開再問大家,無論問哪個國家的人,他們都會異口同聲地回答中國的首都是北京。這就是因為我們往前看的單詞數量已經足夠多了。
但是,當我們把這件事放到歷史課本當中,再去問大家中國的首都是哪裏,這個答案可能就不一定能這麽填了。唐朝的時候中國的首都就應該填長安,馬可波羅到中國的時候,中國的首都就應該填大都。
所以下一個單詞到底怎麽預測,完全取決於我們前面到底提供了什麽樣的上下文資訊,也就是往前看了多久。這種往前看單詞去預測下一個單詞的技術就叫語言模型,它的本質就是這麽簡單。
大模型的全稱就是大語言模型,而它所謂的「大」,我們能看到的是參數量大、數據量大,但實際上它「大」的本質,它的套用需求是可以往前看更長的文本。現在的大語言模型已經基本上可以吞吐到100萬個單詞左右的體量,這才是大語言模型。
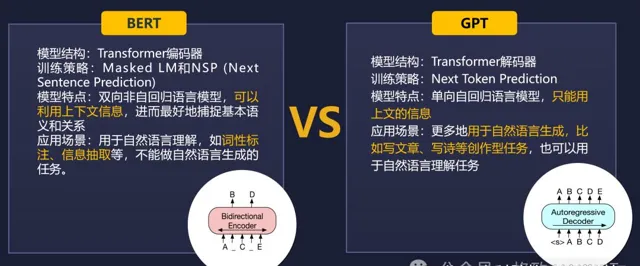
那沒有GPT之前我們在幹嘛呢?難道我們就不做這些任務了嗎?沒有GPT之前,我們用的模型叫BERT,這是一個小模型。
為什麽那時候我們會用BERT模型而不用GPT呢?
原因很簡單。第一,當GPT的參數量很小的時候,它的效果其實很一般,BERT模型完全可以碾壓GPT,所以我們沒有理由放棄一個效果更好的模型。
第二,GPT的參數變大的時候,它需要的算力也更大。說白了就是成本更多,普通的高校和科研院所就負擔不起了。通常來講,我們買幾台伺服器完全可以跑一個小模型,但是想去跑大模型就很困難了,更別提去做大模型的叠代和最佳化了。
BERT這個模型是看兩邊的資訊猜中間,相當於是把句子裏面的某個部份挖了填空。而GPT是只看前面的預測後面的,預測下一個單詞。所以GPT有點像我們跟小朋友在家裏玩接龍。你問他「床前明月」,他就會答「光」;「疑是地上」,他會答「霜」。甚至有的時候,隨著小朋友年齡增長,你只需要提示兩三個字,他就能把後面的句子接出來,這就是GPT。所以BERT用於做自然語言理解的任務更多一點,不能做這樣生成的任務。
所以我們在沒有GPT之前或者在GPT沒有到達這樣一個參數體量、沒有出現智能湧現之前,更多地在用BERT這樣的小模型。
但是,在Open AI公司2022年11月30日釋出了ChatGPT,他們達到這樣一個參數體量、出現智能湧現之後,我們體驗了一周,分析了一周。兩周之後,我們決定要開始這樣的攻關,加強投入,買更多的伺服器,收集更多的語料,訓練中國人自己的大模型。

我們從第一行程式碼開始構建我們的星火大模型,當時定了一個框架叫做「1+N」
。「1」就是一個通用的認知智能大模型。這是一個「基座」,它學習了世界上所有的互聯網知識,對於自然語言的理解不僅僅在文字層面,還有含義層面、語意層面,還有更深層次的內涵等等。這樣它就能夠理解我們想說的話了。
在這樣一個通用大模型的基座之上,我們就可以構建很多垂直行業的小模型,比如教育的模型、辦公的模型、汽車的模型還有互動以及醫療等等的模型。透過把這些領域的知識和語料拿進來,同時還可以用語料去做一些二次預訓練,得到一個更大規模的模型。這樣就可以在特定領域很好地套用。這就是我們做的星火大模型。
這樣的大模型現在效果怎麽樣呢?我們可以給大家看幾個例子。

這是一個影像理解的任務,簡單來說就像小學做的看圖說話。我們可以看到,它生成的效果既有宏觀層面的也有微觀層面的,既有前景的資訊也有背景的資訊。
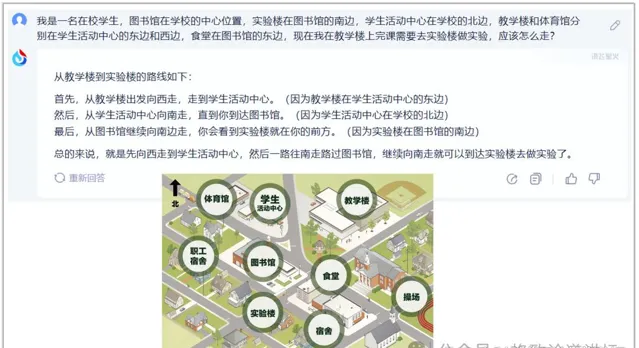
這個是描述一個地圖讓它去理解。它的空間方位感也不錯。所以不僅有圖有真相,更重要的是它還可以是一個活地圖,能幫助我們去理解東西南北。
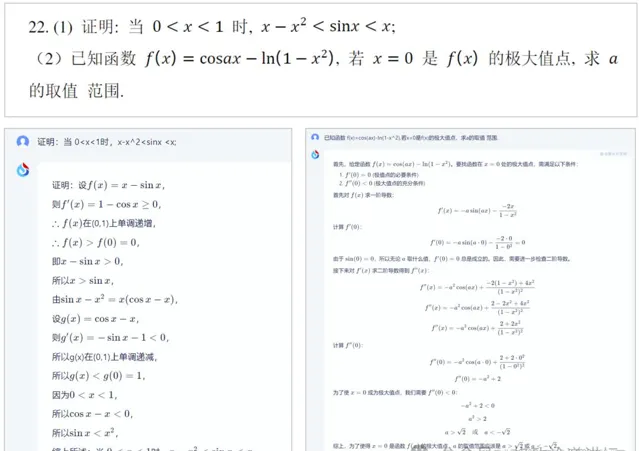
這個例子是我前兩天測試的2023年安徽省高考最後一道壓軸題,我們把它輸入給大模型之後,大模型可以解答這道題,而且答案是完全正確的。看來現在讓機器去考大學基本上是沒有什麽太大的難度了。
一切套用都值得重做一次
既然技術已經發展得足夠好了,是不是就意味著它沒有問題了呢?其實並不是,它還有很多缺陷僅僅靠大語言模型本身沒有辦法解決。今天我主要講兩個。

一個是新知識很難即時更新
。我們在2023年5月6日釋出了星火大模型第一個版本,那時候我們問:剛剛過去的這個「五一」勞動節全國前三天發送的旅客數量有多少,星火和GPT都很難回答出來。
為什麽?因為一個模型的訓練通常需要一個月或者是幾個月甚至更長的時間。隨著參數量的擴大,這個模型的訓練周期會更長。所以大家現在用的大模型實際上都是幾個月之前訓練好的,在它開始訓練的時候到現在發生的這些事並沒有進入它的語料體系裏面,這就意味著它很難獲得新知識。
第二個缺陷是,它會一本正經地胡說八道
,會對一些事實問題張冠李戴、胡亂編造。當我們問它唐朝的第三任皇帝是誰的時候,它會說是唐太宗李世民,但我們都知道是李治。
所以這些問題怎麽去解決呢?我們得從根上找問題。
大家想想,人是怎麽解決這個問題的?我們經常說知之為知之,不知為不知,是知也。你知道的可以回答,不知道的就不要不回答。
比如我現在問大家新中國是什麽時候成立的,大家會異口同聲說是1949年,因為這是知識。但如果我問你塞爾維亞共和國什麽時候成立的,很多人會語塞,因為你不太了解這個冷門的知識。
這個時候人會怎麽做?人會上互聯網檢索資訊,統和一些資訊之後給出答案。這不是知識,這叫邏輯,因為你在用邏輯整合資訊。
在人的判斷裏,人是把知識和邏輯分開的。但是在大模型裏,邏輯和知識是耦合在一塊兒編在神經網絡裏面的。所以要解決張冠李戴和胡說八道的幻覺問題,實際上需要把知識和邏輯分開。
除此之外,我們還要做新知識的更新,我們不可能讓大模型每一次都用最新的知識去自前進演化,所以我們需要接入互聯網,讓它自己從互聯網上找到資訊,對這些資訊做整合。這就是我們講的檢索增強的技術。
所以,靠模型結構裏邊知識和邏輯的解耦,以及檢索的增強,我們就可以讓大模型克服知識難以更新以及張冠李戴的問題了。

有了這樣的大模型技術,我們再回到當時困擾我的那個問題。現在我們把作文批改再做一遍,就可以做得很好,除了可以給學生提供基礎的字、詞、句、段、篇的修改,還可以做一些高級的批改以及給出提升建議,甚至可以給一些最佳化參考。
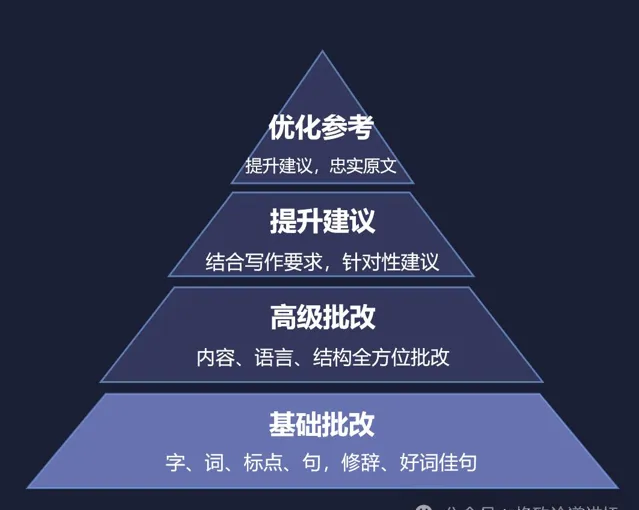
我想,這是大語言模型真正把我們以前想做的很多技術變得可以實作,也讓我們的產品變得更加現實。可以簡單來說,現在互聯網上所有的產品,其實都可以用大語言模型重新再做一遍。
讓AI成為科學家?
我們剛才講的是面向大眾的一些套用。那我們就在想,既然大模型可以完成高考,有上大學的水平,有沒有可能讓它做一些學術性的事情呢?
我們發現這件事是有可能的。因為大模型學互聯網上的知識,實際上只能增長它的見識。但是如果讓大模型去讀科技文獻、讀論文、讀專利、讀標準,它就能增長學術見識。

於是,我們跟中國科學院文獻情報中心合作,做了一個科技文獻的大模型,把論文和專利資訊「餵」給它,讓它去學習。現在,我們就可以在網上讓大模型去做成果調研了。
以前我們做調研的時候,需要看很多文章,然後自己去總結生成一篇綜述。現在你只需要輸入幾個關鍵詞,它就可以大致地給你在這個方向上寫一篇綜述文章出來,總體不超過兩分鐘。
我們以前做研究生的時候需要讀大量論文。粗讀一天能讀5-10篇,精讀一天頂多1-2篇。但在今天,如果把一篇很長的文獻給大模型,大模型可以透過互動的方式,也就是透過問答的方式讓它幫你快速地閱讀,這就可以提升我們的科研效率。
我想,具備了這個能力的大模型實際上就已經有高年級本科生的水平,可以去從事相關領域的研究了。
做到這兒我們還不滿足,於是就進一步想:如果它本科畢業之後想念研究生,應該去念一個什麽樣的專業?有沒有可能變成碩士、博士甚至是科學家呢?我們不斷地求索,希望它從一個科研助手變成真正的科學家同事。
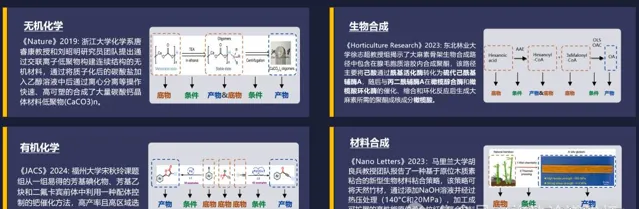
我們選了一個方向叫做合成科學。我們的衣食住行都離不開合成科學,它和化學、材料、生物、環境息息相關。丁奎嶺院士有一句話:「合成科學是通往物質自由的希望之門。」
我們在高中都學過高錳酸鉀分解制氧氣這個實驗。這個實驗需要加熱,加熱之後變成水和氧氣,還有一些其他產物。

但是,物質的合成其實很難。第一個難點是,合成是需要原料也就是受質的。那受質有多少種?光可能成為穩定材料的種類就有10180種,非常多。
第二個難點是條件。外在約束的條件有很多,溫度、壓強等等。而且這種變化既可以是離散的,也可以是連續的,所以它的取值有很多。當多個條件綜合作用的時候,這種組合條件的可能性就更多了。
除此之外,大部份的反應網絡不是一步完成的,而是多步完成的,這種合成路徑也非常多。就好比我從合肥來到北京,既可以坐火車,也可以坐飛機;既可以直達,也可以中轉。怎麽去選擇這樣一個合成反應的網絡路徑呢?這也是非常重要的一件事。

讓我們看看大模型能些到什麽。大模型可以讀取科技文獻裏的各種表格,這裏面就蘊含了我們要用來做化學反應的受質的資訊。接下來,等到我們想要合成一個新物質的時候,它就可以找到相似的合成產物,並且推薦一些可能的受質給他們。
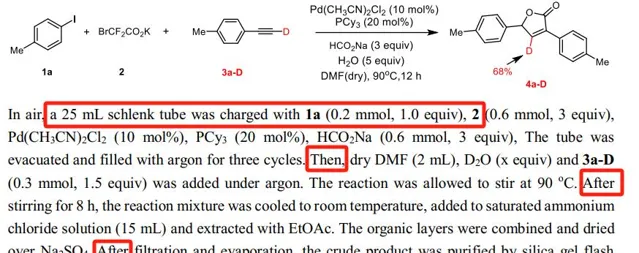
▲為實作氘標記實驗,獲得化學合成物的
反應合成路徑(含受質以及實驗條件)
文獻裏其實也包含了一些反應步驟。除了我們通常在文獻裏能看到的first、second、third(第一步、第二步、第三步)這樣一些比較明顯的英文之外,還可能包含then、after(然後、之後)這樣一些隱式表達。於是大模型就可以知道化學反應到底應該怎麽樣一步一步進行的。
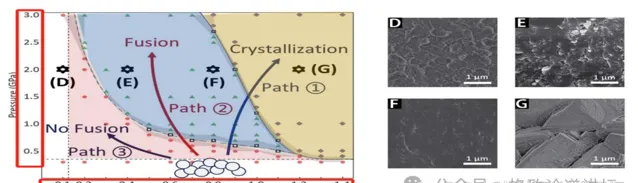
▲為實作無定形碳酸鈣顆粒的融合獲得
不同內部含水量(n)和外部壓強(P)組合比
最有意思的其實是這張圖,論文裏面不僅僅有文字,還有圖和表。這張圖的橫座標是濕度,縱座標是壓強。科學家在做化學反應的時候,並不是所有的產物都需要,他們要的實際上只有中間藍色的這塊,而紅色的和黃色的是殘次品,是不需要的。
這就意味著,做實驗時必須把濕度和壓強控制在一個比較合適的範圍裏。而且這不是線性的控制,是曲線式的控制。合成這個材料的人需要去控制這些條件。
那我們就可以讓讀取影像的大模型去讀這樣的表和圖,然後從裏面把我們需要的條件摳出來,並且在條件和條件之間建立它們的聯系和曲線函數,從而使科學家在未來需要去合成一個新物質的時候,把這樣的條件貢獻出來。
我想,能夠推薦受質,也能夠知道反應的條件,還能夠給出合成的路徑,再配上一些實驗機器人,就可以讓整個實驗流程自動化。那實驗室就不僅僅可以朝九晚五,還可以變成007。而且這不是我們人在「卷」,而是機器在「卷」。
如果這成為現實,那就可以釋放很大的一部份科研精力,讓科學家們去做一些更加天馬行空的設想,攀登更高的科技制高點。
人工智能是站在我們新一代資訊科技革命肩膀上的一個台階。如果說工業革命是把人類從繁重的體力勞動當中解放出來,那麽資訊科技就是把全世界緊密地聯系在一起,正如互聯網把我們連成了「地球村」一樣。而下一個台階的智能革命,則是要把人類從繁重的腦力勞動當中解放出來。
今天,透過以大模型為代表的通用人工智能技術,我們已經能夠看到人工智能的星星之火已開始燃起。

我們也特別希望大家都能夠加入我們,一起讓這樣的星星之火服務於我們的經濟社會和發展,形成促進我們國家經濟增長的新的引擎,形成新質生產力,並形成燎原之勢。
謝謝大家!











