每经记者:李孟林 每经编辑:兰素英
当地时间4月23日,微软推出了开源轻量级AI模型Phi-3系列,宣称这是目前市面上性能最强、最具性价比的「小语言模型」。
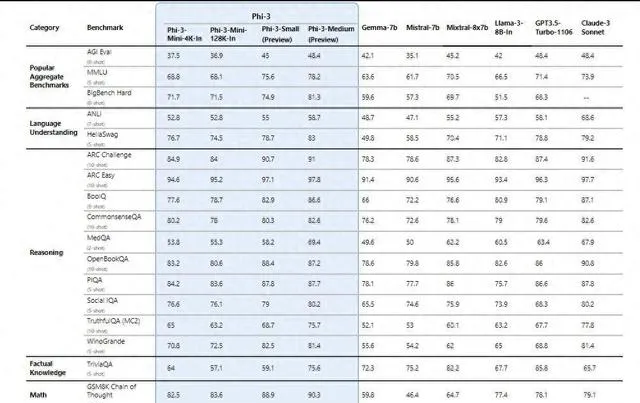
该系列的最小版本Phi-3-mini虽然参数规模仅有38亿,但却展现了超越参数规模大一倍多的模型的性能,在多项基准测试中比Meta的Llama 3 8B更优异,而Phi-3-small和Phi-3-medium这两个版本甚至可以超越GPT-3.5 Turbo。
更令人瞩目的是,Phi-3-mini对内存的占用极少,可在iPhone 14搭载的A16 Bionic芯片上实现每秒12个token的生成速度,这意味着 这款模型不用联网,可以直接在手机上运行。 不仅如此,据透露,Phi-3的成本或只有同等性能模型的十分之一。
这样的模型对于网络资源受限或需要离线推理的场景来说,无疑是一大好消息。据微软介绍,印度企业已经开始用Phi-3模型来帮助资源紧缺的农民解决生产生活问题。但Phi-3系列并非没有缺点,其在事实性知识方面的表现并不理想,不过微软已经找到了相应的缓解之道。
手机上能跑的GPT-3.5级别模型
当地时间4月23日,微软推出了开源轻量级AI模型Phi-3-mini,这是其Phi家族的第4代模型。Phi-3-mini是Phi-3系列中最小的,参数只有38亿,未来几周内,微软还将推出该系列的另外两个版本Phi-3-small(70亿参数)和Phi-3-medium(140亿参数)。
「 Phi-3模型是现有功能最强大、最具性价比的小语言模型(SLM),在各种语言、推理、编码和数学基准测试中,其性能优于相同大小和规模大一级的模型。 」微软方面表示。
具体来看,Phi-3-mini采用了transformer架构,支持4K和128K上下文窗口,也是同类小模型中第一个支持128K的开源产品。
性能上,Phi-3-mini在多项基准测试中超过了参数规模大一倍多的Llama 3 8B(80亿参数),而Phi-3-small和Phi-3-medium超过了很多尺寸大得多的模型,如GPT-3.5 Turbo,而后者的参数规模高达1750亿。
图片来源:微软
由于Phi-3-mini对内存的占用极少,经过压缩后总体积可以大幅缩减至1.8GB,可在iPhone 14搭载的A16 Bionic芯片上实现每秒12个token的生成速度,意味着 这款模型不用联网,可以直接在手机上运行。
Phi-3系列的惊艳表现来自于其训练方式。微软生成式AI研究院(GenAI Resaerch)副总裁Sébastien Bubeck表示,微软在开发Phi-3时力图确保输入的是高质量数据训练集。
微软技术报告显示,开发人员开发Phi-3时使用了3.3T tokens数据集,包括经过严格质量筛选的网络公开文档、精选的高质量教育数据和编程代码。此外,还有AI自己生成的「合成数据」,如数学、编码、常识推理、世界常识、心理科学等。高质量数据,再辅以独特的指令微调和RLHF训练,大幅提高了小语言模型的性能。
当然,Phi-3系列也有其缺点,这主要体现在事实性知识上,在相关的基准测试如TriviaQA上的表现就不如人意。不过,开发语言模型是性能和尺寸的平衡。微软透露, Phi-3模型本身参数中没能力存储太多事实和知识 , 这一缺点的缓解方式是联网接入搜索引擎增强。
可离线使用,成本只有类似性能模型的十分之一
传统观点认为,大语言模型的关键点就在于「大」,参数越大,训练数据体积越大,性能就更强。微软推出轻量级的小语言模型,用意何在呢?
据微软自己的说法, 像Phi-3这样的小语言模型特别适合以下场景:网络资源受限,需要在终端设备上推理或者离线推理的场景;需要避免延迟,快速响应至关重要的场景;成本受限的场景,特别是那些较为简单的任务。
Phi-3能够在手机上离线运行,成本大幅降低,从而大大降低了AI的实际使用门槛。
微软高管Eric Boyd就表示,企业客户经常发现像Phi-3这样的小模型更适合他们的定制应用程序,因为企业的内部数据集本来就规模不大,而且 小模型需要的算力更少,成本也更为便宜。
「 Phi-3的价格不是稍微便宜一点,而是便宜得多,与具有类似功能的其他型号相比,成本差异可能是10倍的范围 ,」微软的Sébastien Bubeck对路透社表示。
微软已经在探索如何在资源有限的情况下应用Phi-3。据其介绍,总部位于印度的商业集团ITC,正在与微软合作将Phi-3用于农业领域,共同开发面向农民的应用程序Krishi Mitra,这一程序的覆盖范围达100万农民。
据悉,农民可以用当地语言向Krishi Mitra提问,该应用程序会立即以用户的本地语言提供详细的个性化响应,帮助他们解决农作物管理、病虫害控制、土壤健康、水资源保护、天气预报、市场联系和政府计划等相关问题。
每日经济新闻











