近日,瓦倫西亞理工大學的研究團隊在【Nature】上發表了他們的最新研究成果:更大的語言模型更不可靠。這一發現顛覆了人們先前的認知,即模型的能力會隨著模型參數量的增長而增長。為了理解這項研究成果的意義,我們先來回顧一些關於機器學習模型能力的研究。
面對新數據「不懂變通」,模型開始「過擬合」!
機器學習模型的學習過程,本質上是在對訓練數據進行統計,並把統計結果儲存在模型參數中。當模型參數量增長時,模型的儲存容量變大,從而可以儲存更多的知識。然而,過多的參數量有時卻反而會導致模型發生過擬合。
過擬合是什麽意思呢?過擬合是指模型過於精確地擬合了訓練數據,以至於無法良好地擬合新的數據的現象,舉一個例子來說明:

過擬合的分類模型
(圖片來源:維基百科)
上圖是一個分類模型的示意圖,圖中的紅色點和藍色點是模型需要區分的樣本,我們希望模型可以找到一個邊界,使得紅色點和藍色點被分到邊界的兩側。
圖中的黑色曲線代表合理的邊界劃分,而綠色曲線代表過擬合時的邊界劃分。這兩條曲線都可以區分模型的訓練數據(無邊框的樣本點),其中綠色曲線的表現甚至更好。但當遇到了新的數據(有邊框的樣本點)時,綠色曲線的表現反而比黑色曲線更差了。
綜上所述,模型在訓練數據上表現更好而在新的數據上表現更差的現象就是過擬合,此時的模型牢牢「記住」了訓練數據中的知識,而在面對新的數據時顯得「不懂變通」。
當一個模型的參數量足夠大時,它總能將訓練數據擬合得很好,因為它可以將訓練數據以某種方式全部儲存在自己的模型參數中。但我們訓練模型並不是為了簡單地記憶訓練數據,而是為了用它來預測新的數據。我們將模型在新的數據上的能力稱作模型的泛化能力,模型過擬合會導致它的泛化能力下降。
在上面的例子中,綠色曲線和黑色曲線都可以良好地擬合訓練數據,我們怎麽知道哪一種更好呢?如果只考慮訓練數據,能夠區分兩類樣本點的曲線實際上有無數條,哪一條能夠在新的數據上表現更好,有更強的泛化能力呢?
奧卡姆剃刀原理:選擇最簡單的方法
在哲學中,奧卡姆剃刀原理給出了這一問題的答案。奧卡姆剃刀原理又被稱為簡約法則,它是指如果有多種理論能對同一問題作出同樣準確的預測,那麽我們應該選擇其中最簡單的一種。
在上面的例子中,所謂的「最簡單的一種」曲線就是需要最少的模型參數的一種曲線。圖中平滑的黑色曲線相比於曲折的綠色曲線需要更少的參數來儲存,而它們的表現相近,因此,根據奧卡姆剃刀原理,我們傾向於選擇黑色曲線作為模型的決策邊界。
奧卡姆剃刀原理已經在多個科學領域得到了驗證。對於機器學習模型來說,簡單的模型和復雜的模型能夠在訓練數據上取得一樣的效果往往意味著簡單的模型抓住了數據的一般性規律,因此簡單的模型在新的數據上也能表現地更好。

模型復雜程度與誤差的關系
(圖片來源:維基百科)
上圖中展示了模型誤差隨模型復雜程度的典型變化,藍色線和紅色線分別代表模型在訓練數據上的誤差和在新的數據上的誤差。
一開始,隨著模型的復雜程度增加,模型在訓練數據和新的數據上的誤差都在減小。但當到達一個臨界點後,模型發生了過擬合,模型在訓練數據上的誤差仍在減小,在新的數據上的誤差反而增加。
因此,為了避免模型過分記憶訓練數據本身的特征,反而忽略了數據的一般性規律,有時我們寧願選擇在訓練數據上表現稍差的模型。
總而言之,當模型的參數量上升時,模型的復雜程度增加,模型在訓練數據上的表現變好,但它在新的數據上的泛化能力不一定會變好,反而可能會下降。為了讓模型在新的數據上取得較好的泛化能力,我們不能無休止地增加模型的參數量。
通用人工智慧的災難性遺忘
對於單一任務來說,增大機器學習模型的參數量無法使模型的能力持續提升。但對於通用人工智慧來說,它需要解決各種各樣復雜的問題,會需要更多的參數,因此增大通用人工智慧的參數量可能對提升模型的能力有所幫助。
然而,如何獲得通用人工智慧仍然是一個懸而未決的問題。現在人工智慧技術在各個領域都有著突出的表現,但人工智慧發展的終極目標是構建出一個能解決任何問題的通用人工智慧,而不是對每一個問題單獨訓練一個特定的人工智慧模型。
如果我們已經有了一個能夠解決A問題的模型和一個能夠解決B問題的模型,應該如何獲得一個既能夠解決A問題也能夠解決B問題的模型呢?我們不能將兩個模型的參數簡單疊加起來,因為這兩個模型它們本身的結構可能並不相同。即使結構相同,參數相互疊加也是沒有意義的,參數中的知識並不能透過疊加而累積,反而會受到破壞。
為了得到能夠解決A和B兩個問題的模型,一個可能的方法是先令模型學習A問題,再讓模型學習B問題。為了使模型在A和B兩個問題上都有良好表現,我們當然需要比只解決A問題的模型或只解決B問題的模型更多的參數。如果模型能將它所擁有的參數一部份分配給A問題,一部份分配給B問題,那麽我們就能預期模型可以同時學習到如何解決這兩個問題。
不幸的是,事實並非如此。在模型學習A問題後再去學習B問題的過程中,往往會發生「災難性遺忘」,即在學習B問題後,模型遺忘了它學習到的關於A問題的知識,因此該模型在A問題上的表現又變得很差。
對於人類來說,我們在學習時會觸類旁通,掌握了某一問題的規律後對於學習同類問題的規律也有所幫助。但對於機器學習模型,先後學習的不同任務會相互抵觸,這使得通用人工智慧難以實作。
通用人工智慧的曙光:大語言模型的「湧現」現象!
在以ChatGPT為代表的大語言模型出現之後,人們仿佛看到了通用人工智慧實作的曙光。語言作為人類溝通的橋梁與一切知識的載體,是人類必不可少的能力。同時,語言也影響著人類的思考方式。因此,通用人工智慧為了學習人類的知識,必然要掌握人類的語言。
大語言模型的學習物件是人類的語言,因此各種不同的問題都可以轉換成語言的形式再讓模型去學習,從而讓模型具有解決多種問題的能力,在一定程度上避免了災難性遺忘的問題。
更加驚人的是,在大語言模型的開發中,研究人員發現增加模型的規模不但沒有出現明顯的過擬合,模型反而產生了「湧現」的現象。
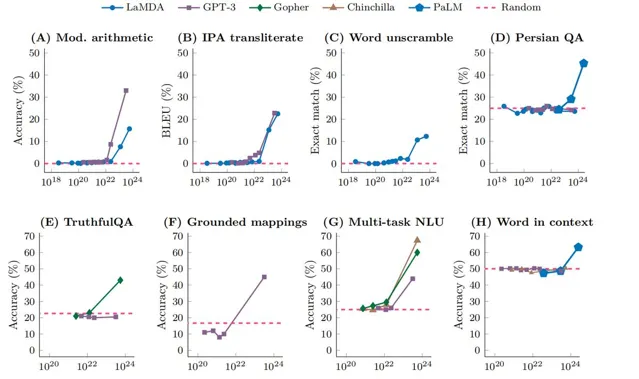
大語言模型的能力「湧現」
(圖片來源:參考文獻1)
上圖中展示了不同大語言模型在不同任務中的精度隨著模型訓練規模的變化,圖中的虛線表示隨機猜測的精度。從圖中可以看到,隨著訓練規模的增加,一開始模型的精度並沒有明顯地增加,仍然和隨機猜測的精度相近。直到訓練規模超過了某一臨界點,模型的能力開始快速隨著訓練規模增加而增加,這種現象稱為「湧現」。
湧現現象在自然界中也能經常觀察到。例如,人類是由細胞構成的,但人類卻擁有單個細胞所沒有的智慧。當孤立的個體構成一個復雜的系統時,可能會湧現出個體所沒有的能力,正所謂量變產生質變。
盡管大語言模型仍然存在著各種各樣的問題,尚未成為真正的通用人工智慧,但不可否認的是,大語言模型代表了人工智慧技術的一次重大飛躍,是如今最接近通用人工智慧的成果之一。
更大的語言模型反而更不可靠?
瓦倫西亞理工大學的研究團隊在【Nature】上發表的最新論文指出,當大語言模型的規模更大更有指導能力後,反而變得更不可靠了。

不同規模大語言模型的指標對比
(圖片來源:參考文獻2)
上圖中展示了研究人員對不同規模大語言模型的可靠性對比的結果,圖中黃色和橘色部份代表較小的模型,藍色部份代表較大的模型。在圖中可以看到,較大的模型在穩定性和正確率上都超過了較小的模型。然而,較大的模型在謹慎度以及難度一致性上,相比於較小的模型,反而表現更差。
謹慎度作為一種評估指標,是指模型在遇到無法解決的問題時回避回答問題的能力,較小的模型較為謹慎,而較大的模型在遇到無法解決的問題時,會直接給出錯誤的答案。
難度一致性是指人類與模型對於問題難度評估的一致性。例如對於人類所認為的較為簡單的加法問題,模型可能會做錯,而對於人類認為較為復雜的科學問題,模型卻能給出較為準確的答案。當模型的規模變大時,模型在復雜科學問題上的準確性大幅提升,在簡答加法上的準確性卻沒有得到足夠提升,這導致難度一致性這一評估指標的下降。
這兩種指標之所以重要,是因為謹慎度的下降讓更大的模型傾向於在不能解決問題時也不承認自己無法解決問題,而是給出一個似是而非的答案,這讓我們更難判斷模型給出的答案是否正確。
同時,當我們使用模型來解決一個特定問題時,根據問題的復雜程度,我們對模型答案的正確性有一個心理預期。當問題較為復雜時,我們並不期望模型給出完全正確的回答,而當問題較為簡單時,我們更傾向於相信模型能夠給出正確的答案。然而,難度不一致性的下降,導致我們會錯誤地估計模型答案的正確性,從而錯誤地相信模型對我們覺得簡單的問題的答案,讓模型變得更不可靠。
正確性的提升表明了更大的模型擁有更強的能力,然而謹慎度與難度一致性的下降則使得更大的模型變得更不可靠。
論文中指出,這可能是因為大語言模型在規模變大和微調的過程中發生了過擬合。在模型的訓練過程中,人們傾向於讓模型總體上有更高的準確率、減少回避問題並更有指導能力,而不是讓模型能夠在簡單問題上完全正確並且在適當的時候承認自己的無知,這導致了模型的可靠性下降。
研究人員表示,為了提升模型的可靠性,在模型訓練過程中,我們需要關註模型的難度一致性,同時將訓練目標從消除模型對問題的回避轉變為教導模型在什麽時候應該進行正確的回避,特別是對於醫學以及其他容錯較小的關鍵領域。
更大的語言模型更不可靠的問題在一定程度上真實存在,但這並不意味著更大的語言模型的能力反而更弱。只是我們先前過於關註模型的能力,反而忽視了模型在真實套用中的可靠性。未來,研究人員需要進一步考慮如何對模型的能力和可靠性進行權衡,從而讓大語言模型能夠取得廣泛的套用。
參考文獻:
-
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., ... & Fedus, W. (2022). Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
-
Zhou, L., Schellaert, W., Martínez-Plumed, F. et al. Larger and more instructable language models become less reliable. Nature 634, 61–68 (2024). https://doi.org/10.1038/s41586-024-07930-y
出品:科普中國
作者:王琛(中國科學院計算技術研究所)
監制:中國科普博覽