近日,瓦伦西亚理工大学的研究团队在【Nature】上发表了他们的最新研究成果:更大的语言模型更不可靠。这一发现颠覆了人们先前的认知,即模型的能力会随着模型参数量的增长而增长。为了理解这项研究成果的意义,我们先来回顾一些关于机器学习模型能力的研究。
面对新数据「不懂变通」,模型开始「过拟合」!
机器学习模型的学习过程,本质上是在对训练数据进行统计,并把统计结果存储在模型参数中。当模型参数量增长时,模型的存储容量变大,从而可以存储更多的知识。然而,过多的参数量有时却反而会导致模型发生过拟合。
过拟合是什么意思呢?过拟合是指模型过于精确地拟合了训练数据,以至于无法良好地拟合新的数据的现象,举一个例子来说明:

过拟合的分类模型
(图片来源:维基百科)
上图是一个分类模型的示意图,图中的红色点和蓝色点是模型需要区分的样本,我们希望模型可以找到一个边界,使得红色点和蓝色点被分到边界的两侧。
图中的黑色曲线代表合理的边界划分,而绿色曲线代表过拟合时的边界划分。这两条曲线都可以区分模型的训练数据(无边框的样本点),其中绿色曲线的表现甚至更好。但当遇到了新的数据(有边框的样本点)时,绿色曲线的表现反而比黑色曲线更差了。
综上所述,模型在训练数据上表现更好而在新的数据上表现更差的现象就是过拟合,此时的模型牢牢「记住」了训练数据中的知识,而在面对新的数据时显得「不懂变通」。
当一个模型的参数量足够大时,它总能将训练数据拟合得很好,因为它可以将训练数据以某种方式全部存储在自己的模型参数中。但我们训练模型并不是为了简单地记忆训练数据,而是为了用它来预测新的数据。我们将模型在新的数据上的能力称作模型的泛化能力,模型过拟合会导致它的泛化能力下降。
在上面的例子中,绿色曲线和黑色曲线都可以良好地拟合训练数据,我们怎么知道哪一种更好呢?如果只考虑训练数据,能够区分两类样本点的曲线实际上有无数条,哪一条能够在新的数据上表现更好,有更强的泛化能力呢?
奥卡姆剃刀原理:选择最简单的方法
在哲学中,奥卡姆剃刀原理给出了这一问题的答案。奥卡姆剃刀原理又被称为简约法则,它是指如果有多种理论能对同一问题作出同样准确的预测,那么我们应该选择其中最简单的一种。
在上面的例子中,所谓的「最简单的一种」曲线就是需要最少的模型参数的一种曲线。图中平滑的黑色曲线相比于曲折的绿色曲线需要更少的参数来存储,而它们的表现相近,因此,根据奥卡姆剃刀原理,我们倾向于选择黑色曲线作为模型的决策边界。
奥卡姆剃刀原理已经在多个科学领域得到了验证。对于机器学习模型来说,简单的模型和复杂的模型能够在训练数据上取得一样的效果往往意味着简单的模型抓住了数据的一般性规律,因此简单的模型在新的数据上也能表现地更好。

模型复杂程度与误差的关系
(图片来源:维基百科)
上图中展示了模型误差随模型复杂程度的典型变化,蓝色线和红色线分别代表模型在训练数据上的误差和在新的数据上的误差。
一开始,随着模型的复杂程度增加,模型在训练数据和新的数据上的误差都在减小。但当到达一个临界点后,模型发生了过拟合,模型在训练数据上的误差仍在减小,在新的数据上的误差反而增加。
因此,为了避免模型过分记忆训练数据本身的特征,反而忽略了数据的一般性规律,有时我们宁愿选择在训练数据上表现稍差的模型。
总而言之,当模型的参数量上升时,模型的复杂程度增加,模型在训练数据上的表现变好,但它在新的数据上的泛化能力不一定会变好,反而可能会下降。为了让模型在新的数据上取得较好的泛化能力,我们不能无休止地增加模型的参数量。
通用人工智能的灾难性遗忘
对于单一任务来说,增大机器学习模型的参数量无法使模型的能力持续提升。但对于通用人工智能来说,它需要解决各种各样复杂的问题,会需要更多的参数,因此增大通用人工智能的参数量可能对提升模型的能力有所帮助。
然而,如何获得通用人工智能仍然是一个悬而未决的问题。现在人工智能技术在各个领域都有着突出的表现,但人工智能发展的终极目标是构建出一个能解决任何问题的通用人工智能,而不是对每一个问题单独训练一个特定的人工智能模型。
如果我们已经有了一个能够解决A问题的模型和一个能够解决B问题的模型,应该如何获得一个既能够解决A问题也能够解决B问题的模型呢?我们不能将两个模型的参数简单叠加起来,因为这两个模型它们本身的结构可能并不相同。即使结构相同,参数相互叠加也是没有意义的,参数中的知识并不能通过叠加而累积,反而会受到破坏。
为了得到能够解决A和B两个问题的模型,一个可能的方法是先令模型学习A问题,再让模型学习B问题。为了使模型在A和B两个问题上都有良好表现,我们当然需要比只解决A问题的模型或只解决B问题的模型更多的参数。如果模型能将它所拥有的参数一部分分配给A问题,一部分分配给B问题,那么我们就能预期模型可以同时学习到如何解决这两个问题。
不幸的是,事实并非如此。在模型学习A问题后再去学习B问题的过程中,往往会发生「灾难性遗忘」,即在学习B问题后,模型遗忘了它学习到的关于A问题的知识,因此该模型在A问题上的表现又变得很差。
对于人类来说,我们在学习时会触类旁通,掌握了某一问题的规律后对于学习同类问题的规律也有所帮助。但对于机器学习模型,先后学习的不同任务会相互抵触,这使得通用人工智能难以实现。
通用人工智能的曙光:大语言模型的「涌现」现象!
在以ChatGPT为代表的大语言模型出现之后,人们仿佛看到了通用人工智能实现的曙光。语言作为人类沟通的桥梁与一切知识的载体,是人类必不可少的能力。同时,语言也影响着人类的思考方式。因此,通用人工智能为了学习人类的知识,必然要掌握人类的语言。
大语言模型的学习对象是人类的语言,因此各种不同的问题都可以转换成语言的形式再让模型去学习,从而让模型具有解决多种问题的能力,在一定程度上避免了灾难性遗忘的问题。
更加惊人的是,在大语言模型的发展中,研究人员发现增加模型的规模不但没有出现明显的过拟合,模型反而产生了「涌现」的现象。
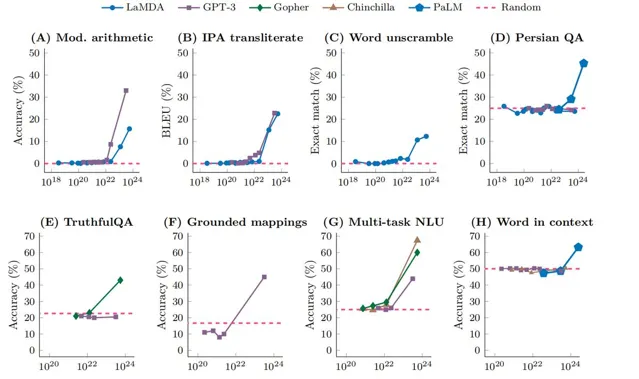
大语言模型的能力「涌现」
(图片来源:参考文献1)
上图中展示了不同大语言模型在不同任务中的精度随着模型训练规模的变化,图中的虚线表示随机猜测的精度。从图中可以看到,随着训练规模的增加,一开始模型的精度并没有明显地增加,仍然和随机猜测的精度相近。直到训练规模超过了某一临界点,模型的能力开始快速随着训练规模增加而增加,这种现象称为「涌现」。
涌现现象在自然界中也能经常观察到。例如,人类是由细胞构成的,但人类却拥有单个细胞所没有的智能。当孤立的个体构成一个复杂的系统时,可能会涌现出个体所没有的能力,正所谓量变产生质变。
尽管大语言模型仍然存在着各种各样的问题,尚未成为真正的通用人工智能,但不可否认的是,大语言模型代表了人工智能技术的一次重大飞跃,是如今最接近通用人工智能的成果之一。
更大的语言模型反而更不可靠?
瓦伦西亚理工大学的研究团队在【Nature】上发表的最新论文指出,当大语言模型的规模更大更有指导能力后,反而变得更不可靠了。

不同规模大语言模型的指标对比
(图片来源:参考文献2)
上图中展示了研究人员对不同规模大语言模型的可靠性对比的结果,图中黄色和橘色部分代表较小的模型,蓝色部分代表较大的模型。在图中可以看到,较大的模型在稳定性和正确率上都超过了较小的模型。然而,较大的模型在谨慎度以及难度一致性上,相比于较小的模型,反而表现更差。
谨慎度作为一种评估指标,是指模型在遇到无法解决的问题时回避回答问题的能力,较小的模型较为谨慎,而较大的模型在遇到无法解决的问题时,会直接给出错误的答案。
难度一致性是指人类与模型对于问题难度评估的一致性。例如对于人类所认为的较为简单的加法问题,模型可能会做错,而对于人类认为较为复杂的科学问题,模型却能给出较为准确的答案。当模型的规模变大时,模型在复杂科学问题上的准确性大幅提升,在简答加法上的准确性却没有得到足够提升,这导致难度一致性这一评估指标的下降。
这两种指标之所以重要,是因为谨慎度的下降让更大的模型倾向于在不能解决问题时也不承认自己无法解决问题,而是给出一个似是而非的答案,这让我们更难判断模型给出的答案是否正确。
同时,当我们使用模型来解决一个特定问题时,根据问题的复杂程度,我们对模型答案的正确性有一个心理预期。当问题较为复杂时,我们并不期望模型给出完全正确的回答,而当问题较为简单时,我们更倾向于相信模型能够给出正确的答案。然而,难度不一致性的下降,导致我们会错误地估计模型答案的正确性,从而错误地相信模型对我们觉得简单的问题的答案,让模型变得更不可靠。
正确性的提升表明了更大的模型拥有更强的能力,然而谨慎度与难度一致性的下降则使得更大的模型变得更不可靠。
论文中指出,这可能是因为大语言模型在规模变大和微调的过程中发生了过拟合。在模型的训练过程中,人们倾向于让模型总体上有更高的准确率、减少回避问题并更有指导能力,而不是让模型能够在简单问题上完全正确并且在适当的时候承认自己的无知,这导致了模型的可靠性下降。
研究人员表示,为了提升模型的可靠性,在模型训练过程中,我们需要关注模型的难度一致性,同时将训练目标从消除模型对问题的回避转变为教导模型在什么时候应该进行正确的回避,特别是对于医学以及其他容错较小的关键领域。
更大的语言模型更不可靠的问题在一定程度上真实存在,但这并不意味着更大的语言模型的能力反而更弱。只是我们先前过于关注模型的能力,反而忽视了模型在真实应用中的可靠性。未来,研究人员需要进一步考虑如何对模型的能力和可靠性进行权衡,从而让大语言模型能够取得广泛的应用。
参考文献:
-
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., ... & Fedus, W. (2022). Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
-
Zhou, L., Schellaert, W., Martínez-Plumed, F. et al. Larger and more instructable language models become less reliable. Nature 634, 61–68 (2024). https://doi.org/10.1038/s41586-024-07930-y
出品:科普中国
作者:王琛(中国科学院计算技术研究所)
监制:中国科普博览