2022 年秋季爆發的生成式 AI 炒作似乎仍然沒有消退——因此,直到 2024 年第二季度初,台灣芯片制造商台積電是迄今為止世界上唯一一家不僅能夠根據所需生產標準制造必要芯片,而且還能夠使用最先進的「三維」CoWoS 技術封裝它們的芯片(chip-on-wafer-on-substrate),幾乎無法應對相應芯片設計人員穩步增長的訂單流;主要來自輝達。現在,幸運的是,新的CoWoS封裝線開始在台灣投入營運,因此有興趣的伺服器影片卡制造商可供購買的芯片數量(當然,稱它們為 張量電腦 更準確,因為它們已經很久沒有專門用於生成電腦影片了)每個月都在增長,因此,全球AI產業發展的瓶頸已經擴大。

光子學尚未達到用純光制造芯片的地步,但麻煩已經開始(來源:基於 SDXL 1.0 模型的 AI 生成)
唉,緊接著,另一個不幸發生了,這是 Meta 負責人馬克·朱克伯格 (Mark Zuckerberg) 最近講述的,該公司積極參與人工智能競賽——好吧,因為元宇宙沒有「起飛」,公眾已經愛上了智能機器人。現在,適合訓練假設的 GPT-5(以及來自 OpenAI 以外的開發人員的未來類似物)的數據中心的擴張受到平庸但同樣令人遺憾的電力短缺的阻礙。直到 2022 年底,當對生成式 AI 最廣泛的興趣開始像雪崩一樣增長時,典型數據中心中的單個機架消耗的電力在 10-15 kW 範圍內。今天,考慮到目前平均機架沒有配備單個張量電腦來響應客戶要求,其功耗達到 40-60 kW。因此,一個大型超大規模數據中心的峰值容量可能需要 150 MW,據專家稱,僅美國數據中心的總能耗就從 2022 年的 17 GW 飆升至 2030 年的 35 GW。
這才是真正的問題:盡管地球上居民可用的能源資源可能是無限的(僅來自太陽的光子流顯然就涵蓋了未來幾個世紀人類對能源的所有需求),但當將這種潛力轉化為為非常特定的器材提供動力的平凡千瓦時時,困難就開始了.此外,現代半導體計算器材在能耗方面效率極低,稱其為能源浪費更為正確。任何將「1」轉換為「0」或反之亦然的邏輯操作都簡化為在很小的距離內移動非常小的電荷,即產生微電流。反過來,任何電流都會加熱它流過的通道,如果這個通道有電阻(它確實如此,因為序列半導體芯片不具有超導特性)。結果,在給定芯片中執行的邏輯操作每秒產生的數萬億微電流轉化為數十瓦和數百瓦的功率轉化為熱量。然後你需要花費大量的能量來去除這種寄生熱量,否則過熱的芯片將無法正常工作。
因此,伺服器內部帶有半導體芯片的經典數據中心數量的廣泛增長顯然無法從根本上解決即將到來的AI任務缺乏計算能力的問題。有幾種方法可以解決這個問題,但當今最有前途的方法之一是光子學,從「光子」+「電子」——使用 光學 邏輯電路代替電子電路或與它們一起使用。 人類 很久以前就學會了以光脈沖的形式傳輸資訊,並且仍然很好地實踐了這項活動——從山峰上的訊號火到日光儀再到光纖通訊路線。但是,使用光子來組織邏輯電路,並在其基礎上組織超大型 計算電路 是一項更加困難的任務。

1917 年,土耳其訊號員在陣地上使用日光儀(來源:Wikimedia Commons)
然而,它的決定已經得到了全世界的認真對待:只要回想一下,在2024年春季結束時,總理米哈伊爾·米舒斯京(Mikhail Mishustin)設定了確保俄羅斯在光子學領域十大領導者中的地位的任務。這是很合乎邏輯的:如果在半導體 VLSI 領域趕上行業領導者是非常困難和昂貴的(就在 2024 年 5 月 21 日,俄羅斯聯邦工業和貿易部副部長瓦西裏·什帕克正式宣布,第一台國產光刻機已經建立並正在俄羅斯進行測試,確保按照高達 350 nm 的生產標準生產芯片——可與台積電和三星電子目前的「3 nm」相媲美), 在光子學領域,所有準備踏上這個領域的玩家今天都處於幾乎平等的地位。而且,由於人工智能在傳統芯片上的進展是故意停留在能源上限上,因此立即專註於不受這些限制的發展分支要合理得多。
需要更多的數據(和能量
AI計算的半導體硬件基礎的主要問題就是他們!— 本質上是多執行緒 神經網絡的功能是 線上性二 進制邏輯的基礎上模擬的。在關於神經計算基本原理的文章中,我們解釋了人工神經元是如何工作的,即感知器,它接收來自多個輸入的輸入訊號,並根據一定的規則,在輸出端產生一個結果訊號,以及它們如何組合成(現在通常是多層的)神經網絡。從技術上講,感知器並不那麽復雜,這使得在最普通的馮·諾依曼電腦的記憶體中建立它們的大量虛擬影像成為可能。
是否有必要在物理上模仿大腦的結構,以達到神經網絡的根本新復雜程度?這個問題仍然沒有答案(來源:基於 SDXL 1.0 模型的 AI 生成)
另一件事是,神經網絡的工作歸結為執行數量驚人的簡單操作(加權求和——與參數對相乘的加法),馮·諾依曼系統被迫在實際計算節點(處理器)和數據儲存(RAM)之間主動流動數據以執行此類計算。這就是為什麽具有成百上千個計算內核的強大圖形介面卡,再加上具有高效能影片記憶體的高速數據總線,可儲存數 GB(甚至數十 GB)的高效能影片記憶體,適合執行,更適合以當今廣泛使用的最佳方式訓練 AI 模型。是的,專用模擬電腦能夠在人工智能任務上與基於二進制邏輯的經典電腦競爭,但這種電腦的大規模生產和實施仍然是一個相當遙遠的未來。
為什麽今天幾乎所有的虛擬神經網絡都在實踐中使用,在馮·諾依曼電腦的記憶體中執行,由感知器層表示?畢竟,沒有什麽可以阻止 - 特別是因為我們仍在談論RAM中這些物件的 模擬 - 從一個特定感知器的輸出向任何其他感知器的輸入發送訊號,順便說一句,這將與高等動物大腦中生物神經元之間的相互作用結構更加一致。這一切都與計算最佳化有關:透過將虛擬神經元排列在層中,使給定層的元素的輸出與一個元素的輸入和下一個元素的輸入閉合,您可以自由地使用線性代數中已知的矩陣運算來加快計算速度。正是透過這樣的操作,馮·諾依曼電腦(我們記得,數碼神經網絡功能)能夠出色地應對。
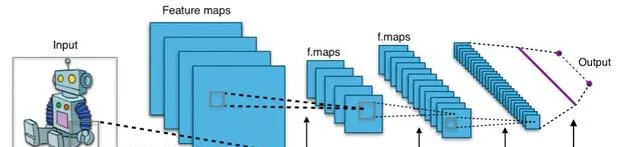
摺積神經網絡的工作原理(來源:Wikimedia Commons)
矩陣運算的一個很好的例子是摺積,它使得在機器學習領域(或者更準確地說,視覺影像辨識)領域取得重大進展成為可能,我們在關於摺積神經網絡的文章中對此進行了詳細討論。套用於模式辨識的多層神經網絡的主要問題是,當試圖誠實地處理 整個 輸入影像時(具有任何足夠的分辨率,例如512×512像素加上另外3位用於顏色編碼),系統必須處理過多的參數,每個參數都必須不可避免地參與加權求和操作。不僅如此,為了訓練這樣的網絡來辨識某些影像,你必須給它提供適當數量的參考影像——分別與貓、單獨與狗、單獨與馬,依此類推,對於所有最終需要辨識的物件。另一方面,摺積網絡透過從根本上降低矩陣的維度來辨識原始影像的各個片段的某些特征,從而減少整個模型的操作參數數量。而且,即使在開放(用於非商業研究)ImageNet數據集(超過2萬個類別的1400多萬張影像)等相對適度的材料上,它們也使其訓練非常逼真。
然而,今天,更強大的神經網絡正在使用中:GPT-3 已經包含 1750 億個內部參數,其有效值是在 3000 億個代幣的數據集上訓練後建立的。根據 Epoch 研究所的 Pablo Villalobos 的說法,GPT-4 是在 12 萬億個數據代幣上訓練的,目前互聯網上可用的所有資訊可能根本不足以充分訓練下一代模型——其數量不超過 20 萬億個代幣(而有條件的 GPT-5 可能需要,具體取決於其實作的細節,從 60 到 100 萬億個代幣)。正在積極討論使用那些已經在工作的神經網絡生成缺失數據的可能性,以便將從它們獲得的代幣提供給有前途的模型。然而,許多研究人員批評了這條道路,指出在衍生數據(而不是直接從自然或人造中獲取)上學習的潛在危險,如模型崩潰、過度擬合、機器「幻覺」滲透到數據集中(每個人都記得熊在太空中的故事?)但是,即使數據問題以某種方式得到解決,半導體計算器材能耗過剩的障礙也不會消失,而有條件的 GPT-5 必須在此基礎上進行訓練。至少在光子學取代微電子學之前,至少在當今高科技領域這個相對狹窄但極其重要的領域。
光明之路
從能源效率的角度來看,光子是一種比電子更具吸重力的粒子。就數據傳輸密度而言,導波中的光通量先驗優於沿導體移動的電子群:自 1970 年代後期以來,世界各地的光纖長距離通訊路線開始自信地取代銅線,這絕非巧合。光通訊通道也越來越多地用於數據中心內甚至電腦集群的各個計算節點之間的高速數據傳輸:它們保證了更高的速度和更少的能源消耗。鑒於資訊傳輸的速度和密度對神經網絡計算的重要性,我們可以預期光子學在這裏將比我們今天習慣的電子產品更具吸重力。

基於半導體的雪崩光電探測器完全有能力成為純聲子和純電子計算電路之間的連結(來源:英特爾)
然而,資訊 的傳輸 與其 處理 之間存在巨大的距離,即根據其內部配置設定的某些規則,在狀態「1」和「0」之間有條件地切換某個邏輯門。半導體晶體管的卓越品質是非線性的,到目前為止,它已經自信地彌補了幾乎所有非常明顯的缺點:其工作參數(首先是電阻)對外部電流和電壓的依賴性。線上性電路中,其元件的特性(電阻、電容、電感)是恒定值,輸出電壓始終與輸入電壓成正比——當然,在合理的範圍內;直到由於輸入電流參數過高而發生擊穿。對於非線性電路來說,情況並非如此,正是這種非典型行為允許特殊選擇輸入參數以獲得不同的輸出,即最終實作邏輯電路的各種元件。
光子是完全不同的事情:它們在介質中沿直線運動(更準確地說,沿著測地線,但在這種情況下,考慮廣義相對論的影響是沒有意義的),服從麥克斯韋 的線性 方程式。因此,如果我們不考慮其中不可避免的光散射/衰減,光學器件是無藝術線性的:它們的輸出流的功率通常與輸入流的功率成正比。那麽,邏輯輪廓應該如何組織呢?「阻礙我們的東西會幫助我們」——當然,我們之前關於微處理器生產的成功和問題的讀者已經了解了這種非常高效的工程方法的本質。事實上,通用半導體邏輯的基本元素的直接再現,例如使用光子發射器和轉換器的Schaeffer行程,目前是無效的(盡管這方面的工作也在進行中)。
以下邏輯鏈更加巧妙:實際的 AI 任務被簡化為矩陣上的操作;矩陣上的運算透過線性代數進行研究;線性電路可以很容易地建立在光子器件上——這一切難道不意味著光子學,而不是半導體版本的經典微電子學,是加速人工智能領域進步的最佳選擇嗎?事實上,矩陣乘法通常用於(深度)機器學習,可以由混合光子器件執行 - 最少地使用最簡單的半導體電子器件 - 比基於純矽的經典電腦系統更有效。
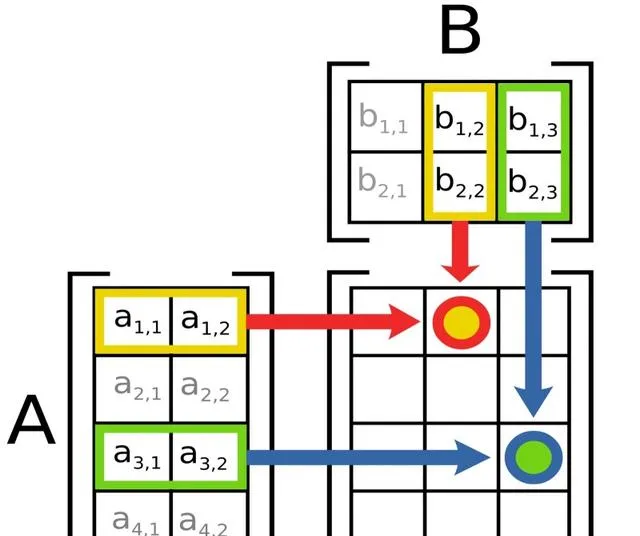
矩陣乘法很容易(來源:Wikimedia Commons)
對於那些忘記了線性代數基礎知識的人,我們提醒您,您可以將此類矩陣相乘,其中第一個矩陣的行數等於第二個矩陣的列數(在這種情況下,因子的順序很重要)。在生成的矩陣中,每個座標為 (n , k ) 的元素都是兩個數值向量的點積,第一個因子的 第 n 行與第二個因子 的第 k 列。乘法和加法本身就是基本過程;現代矽微處理器,尤其是多核和多執行緒微處理器,開玩笑地應對它們。唯一的問題是,機器學習問題使用大維矩陣進行操作,而在不求助於復雜的最佳化的情況下,將兩個 大小為 m × m 的正方形矩陣相乘所需的運算元量約為 m ³(在數學符號中, O ( m ³;讀作「O large of em in a cube」),當然,這已經是數萬 米 了開始在電腦系統的硬件基礎上建立公平的負載。與其說是在處理器上,不如說是在處理器和記憶體之間的總線上,中間結果所在的總線上,因為讓我們再次回顧一下,馮·諾依曼架構意味著計算節點和資料倉儲之間的空間分離。
由於數學家的巨大努力,幾十年來,矩陣維數為估計乘法所需步數的程度的指標已從大約 2.80 減少到 2.42,自 2023 年底以來, 數碼 2.371552 被認為是最好的成就(在此之前,記錄值是 2.371866)——在實踐中,該指標每減少萬分之一就極其重要。 以美元和千瓦時表示。重要性越大,每個新的機器學習模型開始處理的矩陣就越大。
除法和乘法
2019 年,麻省理工學院的 Ryan Hamerly 及其同事提議使用基於分束器的光電電路——粗略地說,半透明鏡子與落在它上面的光通量軸成 45° 角旋轉——來增加矩陣。由於反射鏡是 半透明 的,因此正好有一半的原始流動(在第一個近似中可以忽略不可避免的吸收/散射損失)以相同的方向透過玻璃板,而另一半則如預期的那樣以90°角反射到該方向。分光鏡顯然不適合任何邏輯電路的作用——它只會將光子流分成強度相等的兩部份,彼此垂直傳播。
基於原始分光鏡的光電倍增器(特別是矩陣)示意圖(來源:IEEE Spectrum)
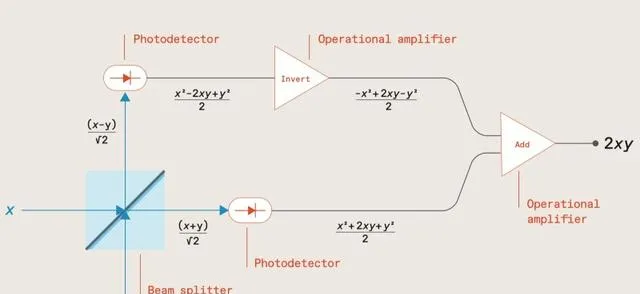
然而,第二束可以指向同一束流分流器,在第一束初始光束落下的同一點(僅從板的背面),與第一束成 90° 角。同樣的事情也會發生在它身上,結果將是一個具有兩個輸入和兩個輸出的光學系統,每個傳出流都將是傳入流的組合。一個簡單的分光鏡在原始方向上正好傳輸一半的光束不會提供值得註意的結果,因為兩種出射(組合)光線的強度將相等。Hamerli和他的同事們提出了一種更復雜的裝置,它在一個方向上接收電場強度 為x ,在另一個方向 上具有y 的光束,在第一個輸出通道中發射強度為( x + y )/√2的流,在第二個方向發射強度為( x − y )/√2的流。
此外,在光學方案中,在出射光束的路徑上有光電探測器,用於測量光通量 的功率 ,該值與該通量中電場 強度的平方 成正比。因此,( x + y )/√2 是 ( x 2 + 2 xy + y 2)/2,( x − y )/√2 是 ( x 2 − 2 xy + y 2)/2。然後兩個運算放大器開始工作,第一個運算放大器反轉其中一個光電探測器的輸出(將 ( x 2 − 2 xy + y 2)/2 轉換為 (− x 2 + 2 xy − y 2)/2),第二個只是將獲得的值相加。結果為值 2 xy ,即 線性 光電電路實際上乘以初始光通量的電場強度值編碼的初始值 x 和 y (附加系數為 2,但這根本不是問題)。此外,這些流不必在時間上是連續的:例如,矩陣中的數碼可以透過連續和非常短的脈沖進行編碼,這些脈沖對兩個輸入通道都是時間匹配的。
還行;這個方案可以讓你得到一個乘積,但是在乘以矩陣時,還需要從相應的單元格中將每對連續數碼的乘積 相加 ,對吧?這也沒有問題:在電路上的最後一個運算放大器後面放置一個電容器就足夠了,這將積累部份電荷,與該放大器產生的下一次功率成正比。整個電路的線性度及其模擬特性再次受到工程師的註意:事實上,在測量電容器計數器中一系列光脈沖結束時積累的電荷量時,這裏需要將連續值轉換為離散值的唯一轉換器。

Ryan Hamerley的團隊和MTI的同事提出的光子芯片設計的電腦模型(來源:IEEE Spectrum)
現在讓我們回想一下,這樣一個序列的持續時間——可乘矩陣的列數/行數——可以對應於神經網絡模型處理的參數碼段的維數。換句話說,如果這個維度是 N ,那麽在馮·諾依曼電腦上,將這樣的矩陣相乘將需要 O ( N 3)——好吧, 即使 O ( N 2.371552)——運算。Hamerli和他的同事們的光電電路將以 N 個步驟應對這樣的任務,光源形成的脈沖頻率越高(並且由於現代激光技術的成功,它可以達到數百太赫茲,如美國ZEUS,Zetawatt等效超短脈沖激光系統),計算速度越快。
如果沒有布爾
除了從根本上加快大型人工智能模型執行中最耗費資源的操作之一外,從「純」微電子向光子學的過渡在能源效率方面也提供了巨大的好處。很明顯,高頻脈沖激光器的執行可能需要相當大的功率,但是由於其操作的 可逆性 ,基於光學元件的計算電路從根本上優於基於具有 不可逆 邏輯的元件的半導體系統。這一點值得單獨解釋,因為它使我們能夠看到基於布爾代數的經典電腦的基本局限性——正是為了解決與人工智能相關的大規模和資源密集型問題。
透過帶有兩個參數的邏輯運算「AND」的例子,很容易理解「不可逆邏輯」的含義:如果兩個參數都為真,則為「true」,如果其中至少有一個為假,則給出「false」值。換言之,基於結果——相應邏輯門輸出端的「1」或「0」——只有在四種可能的情況下,才有可能可靠地建立傳入參數的值:如果「邏輯AND」返回「1」,那麽兩個參數的值都為「true」。在涉及至少一個「0」的所有組合中,有關操作初始參數的資訊將遺失。
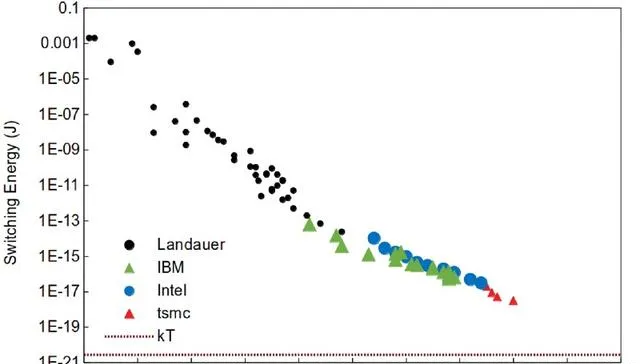
使用今年的工藝技術切換單個半導體晶體管所需的能量正在穩步下降,但Landauer極限(虛線水平線)仍然無法實作(來源:LessWrong via Landauer,IBM,Intel和TSMC)
為什麽從能源的角度來看它很重要?因為資訊遺失意味著系統熵的增加,從物理意義上講,意味著計算電路內能量的耗散。根據Landauer的原理(當時的IBM員工Rolf Landauer在1961年制定了該原理),在任何計算系統中,無論其物理實作的細節如何,當每一點資訊遺失時(特別是在不可逆閥門的操作過程中),都會釋放出一定量的熱量。請註意,這種規律性是純粹的熱力學性質,表明基於不可逆邏輯門的電腦能量損失的非零下限。例如,由於(半導體)導體的電阻而產生的額外(以及更重要的)耗散,這列根本沒有考慮。
是的,Landauer 設定的值非常小——每損失一個位元,它就小於 3 × 10−21 J,但現在讓我們再次記住現代馮·諾依曼電腦產生不可逆的基本邏輯運算,使用生成式 AI 模型解決某些問題。2012 年,Landauer 原理在實驗上得到證實,2018 年,基於分子納米磁體物理基礎的量子計算出現了其有效性的證據,這在未來為具有不可逆邏輯門的量子電腦設定了能耗下限。現代微電子技術,尤其是那些基於矽以外的半導體的微電子技術,每一代都變得越來越節能,因此預計在未來幾十年內將達到它們的Landauer極限。預測是相當現實的:截至 2020 年,將晶體管柵極從「閉合」位置或「開啟」位置或返回所花費的能量僅比該限制高三個小數點後幾個數量級,而在 2000 年,差距超過了六個數量級。
另一方面,光子學主要依靠可逆邏輯門,可以執行至少部份計算,能耗在Landauer極限水平上,其中一些非常重要。當然,在發展高計算技術這一分支的道路上必須克服許多障礙,我們將在下一篇文章中討論這些障礙。但從將矩陣乘以10-6個或更多元素的能力的角度來看,不需要專用的核電廠來為執行此類操作的數據中心供電,光子學絕對值得付出努力。











