从网页上抓取数据,也就是常说的爬虫功能,这个有什么用处呢?就拿百度来讲,大量的数据都是通过网络爬虫的方式获取,然后进行索引,排版,然后再通过搜索入口提供给大家。一些网站或者应用会有我们需要的数据,而且数据是经常变动的,比如购物网站商品的价格,一些比价网通过定期抓取商城的价格,然后记录下来,根据商品id形成价格的波动表,这样再买商品时就能清楚地知道自己购买的是否划算。说了这么多,我们从基本的urllib模块来获取一个网页的html代码,并从中获取想要的数据。

获取气象网站的链接数据,代码如下:
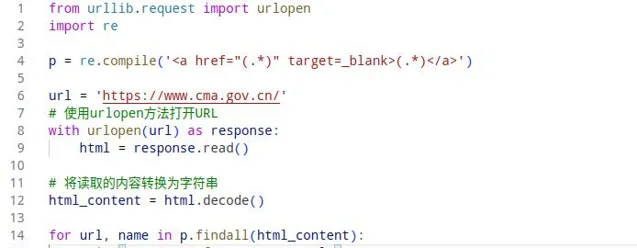
通过正则表达式获取链接数据
执行结果:

执行结果
正则表达式的方式获取文本比较灵活,但对于获取网页数据来讲还是比较复杂了,毕竟网页html是标准结构的,同时html也会存在复杂的结构,导致正则表达式很难编写与维护,这里引入一个新模块Beautiful Soup,它是一个小巧而出色的模块,还可以用于解析在Web上可能遇到的不严谨且格式的HTML,上面的代码改写如下:
首先需要安装模块:
pip install beautifulsoup4
代码:
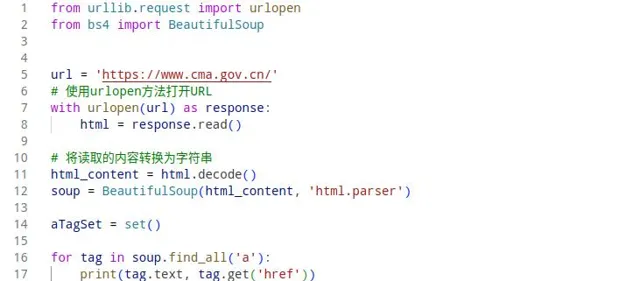
BeautifulSoup解析html
执行结果:

执行结果
Beautiful Soup常用方法:
find_all("标签名") 返回标签的列表,标签主要有:链接a标签,列表ul标签,li标签,模块的div标签等。
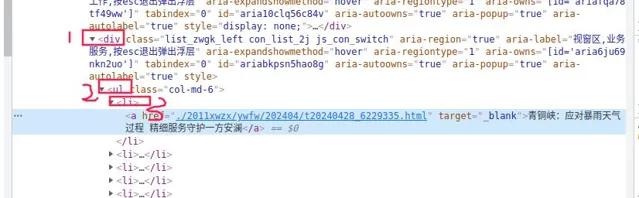
select("标签的层级") 返回列表,比如select("div ul li"),html的结构如下图:
以上就是网页抓取的简单介绍,了解更多精彩分享,敬请关注哦。











