过去的人工智能技术,在进行自然语言处理的时候,只能理解字面的意思。为了训练出中国人自己的大语言模型,科学家「喂」给它论文和科技文献,让它进行学习,从「助手」变为「助研」…
出品:格致论道讲坛
以下内容为科大讯飞AI研究院副院长李鑫
演讲实录:
大家好,我是来自科大讯飞AI研究院的李鑫,今天演讲的题目叫【最后一个需要人来解决的问题】。
我想可能很多人都能猜到,这是一个关于人工智能的话题。我们往往会把人工智能发展史分为3个台阶,一个叫计算智能,一个叫感知智能,第三个叫认知智能。
很显然在计算智能时代,计算机已经完全碾压人类了,无论是运算速度还是存储容量都比人要强大很多。到了感知智能时代,我们会提到智能语音、图像处理技术,经常说要「让机器能听会说」。那么感知智能现在发展得怎么样了呢?我想给大家举几个例子。
我们先来看看让机器「能听」,这指的是语音识别技术。
输入一段语音,它就能够输出相应的文字,相当于让机器长了耳朵。这张图上是2010年我们发布的讯飞输入法。现在语音输入已经是件稀松平常的事了,但在那个时候,把语音输入实时变成文字还是件稀罕事,给我们的生活工作提供了非常大的便利。
现在这个技术发展成什么样了呢?我们来看这个视频。视频里的外国人说的是他们国家的语言,他的话通过语音识别技术转换成了英文字幕,再翻译成我们能听得懂的中文。
现在的语音识别技术不仅仅能应用在安静的、像大会一样的场景下,还在往更复杂的场景延伸。比如在一些公共的场合里有很多噪音,某些居家的场景下有很多回响,还有一些很复杂的环境像可能有「鸡尾酒效应」的酒吧等等,这些干扰都在逐渐地被语音识别技术研究者攻克。
说完了「能听」,我们再来看看这个「会说」。机器的「会说」指的是语音合成技术,它实际上是语音识别技术的一个逆过程。
识别是语音生成文字,而合成是文字生成语音。
这是我请来的一位神秘的嘉宾,大家能听出来他是谁吗?特别热爱学习的同学能猜出来,他是「得到」的创始人罗振宇先生。这个声音是合成的,并不是他本人说的。
这样的合成技术并不是明星或者流量IP的专利。现在我们普通人说几分钟的话,就可以基于说话人的声音提取出声纹,生成你说任何语言的声音。
对于一些经常出差的人来讲,虽然人出差了,但完全可以用自己的声纹在家里给小朋友讲故事、读绘本。这是语音合成技术的一个应用,只闻其声、不见其人。
现在我请我们的虚拟人同事「小姿」和大家打个招呼。刚才是只闻其声、不见其人,现在是既闻其声、也见其人。不仅声音可以变得非常鲜活,形象也可以惟妙惟肖。它的唇型是由声音来驱动的,说出什么样的声音,就会形成什么样的唇形,和真人是一样的。
「能听」和「会说」构成了我们的语音识别和语音合成技术,在这些技术的背后,互联网起着非常重要的作用。
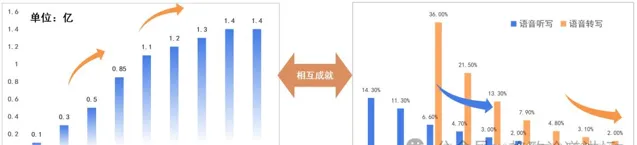
▲左:讯飞输入法月活数据逐步上升
右:科大讯飞语音识别错误率每年相对下降30%以上
我们有一个名词叫「涟漪效应」,
它指的是当我们的用户数上升时,用户贡献的数据量也会增多,技术的水平也会随之逐渐地提升。所以当我们讯飞输入法的月活用户逐渐增多的时候,语音识别的错误率每年会相对下降30%左右。
这就是我们说的,数据越多,模型迭代得越好;模型迭代得越好,
就会有越来越多的人愿意去使用我们的产品;而用户增多又会产生更多的数据
,这样就会形成一个正向的良性循环。
如果没有互联网,这些鲜活的数据是没有办法反馈回来的,模型的迭代也会非常地缓慢,这就是互联网让人工智能技术进步的一个最大、最重要的作用。
怎么理解中文的博大精深?
说完了「能听会说」,我们自然而然就要迈到第三个台阶,认知智能。但是,认知智能在做自然语言处理时会出现很多的问题
,我们给大家举几个例子。

比如「冬天能穿多少穿多少,夏天能穿多少穿多少」。仅仅是季节不同,其他文字没有发生任何的变化,但是前半句和后半句的语义完全不同。前面是让我们要尽可能保暖,后面是让我们尽可能清凉。
再举个例子,「校长说身上除了校徽别别别的」。我今天上场的时候,组织方给我这贴了「格致论道」的标识,除了这个标识之外,别别别的。这里的「别别别」看起来是同一个字,但是语义完全不同。第一个「别」是不要的意思;第二个「别」是佩戴的意思,是个动词;第三个「别」是代词,指代其他的东西。所以如何让计算机理解「别别别」的这种一词多义也是我们做认知智能时一个非常重要的挑战。
再比如说,我们的中文和英文之间还有一个很大的不同点。英文的词和词之间是有空格的,中文没有。所以怎么样去切词也是处理中文的一项很重要的挑战。

这个横幅正常的读法是「三餐二楼欢迎新老师生/前来就餐」。但如果断句不当,就会闹出笑话,断成「三餐二楼欢迎新老师/生前来就餐」。中华文字的博大精深,实际上很难被AI完全掌握。AI面对中文,有点儿捉襟见肘。

之所以会这样,一个很重要的原因就是我们看到的仅仅是文字,但是文字底下蕴含的这些知识、常识和逻辑才是我们理解文字的重要基础。
如果我们无法感知夏天和冬天的变化,没有这种常识,就没有办法理解什么叫做「能穿多少穿多少」。如果我们不知道什么叫做一词多义,没有这种知识,就没有办法理解什么叫做「别别别的」。
所以,让机器「能听会说」的下一个台阶就是「能理解、会思考」
,语言是非常重要的一个核心。
2010年我硕博连读时,就一直在做自然语言处理的工作。今天互联网上正在发生「百模大战」,「模」指的就是各家的大语言大模型。那在当时恰逢百「团」大战,
百「团」大战就是指很多团购网站在一起去竞争。这面的一个核心技术叫推荐系统,就是你喜欢什么,我就给你推荐什么,这会使电商有很高的营单量。

我当时做的事情就是分析大众点评和美国的Yelp网站上面的用户评论数据,从而给用户推荐适合他们喜好的东西,比如一些合适的餐馆或者菜品,以及他们可能会认识的人或者喜欢的人。这些也都要基于用户的文本来进行挖掘,所以一直在做语言文字相关的工作。

恰好科大讯飞在2014年提出说要让语言和语音成为机器认知革命的入口,还发布了讯飞超脑计划,也就是要做自然语音处理。正是在那次的发布会上,他们提出来「要让机器能理解、会思考」。
我觉得这些和我的方向还是挺接近的,所以在2015年博士毕业后,我就顺理成章地加入了讯飞,继续从事相关的研究工作。
90分和88分的作文区别在哪?
我进入到讯飞之后,做的第一件事就是作文批改。这个需求是很自然的。
以前读书的时候,老师布置一篇作文很简单,就是把一个题目给大家,每个同学写500-800字的文章交给老师。但是,批改作文要比布置作文痛苦得多,因为每个学生的文章都得看。所以那时候,老师能画几个波浪线,我们就觉得心满意足了。
但是,几个波浪线并不能帮助我提升写作水平,因为我不知道怎么样写才能写得更好,老师没有做详细的评语,因为如果所有同学的作文都让老师批改的话,老师的工作量也很大。
于是我们就想,有没有可能可以用人工智能技术里自然语言处理的方式来减轻老师的工作量,还能让学生在写作上有更好的提升呢?

所以我们第一个任务就是作文批改,这项任务的第一个工作就是得分预测。这篇文章如果是100分制的,我们大概能给这个文章打多少分。
这个问题相对比较简单,因为在长时间的教学过程中,老师们已经总结出了很多给作文评分的纬度,比如词汇量、优美的语句等等。我们完全可以根据这些教学中的方式方法,从文本里提取这些特征,然后把这些特征和最后得分做一个映射。
用人工智能技术来做得分预测的问题很快就迎刃而解了。但是这个问题解决之后,还没有满足老师们的需求。他们特别期待地说,这个文章得了94分,为什么?你能不能展开说说?
这就比较困难了。展开说说就意味着你要解释写得好的地方好在哪儿?写得差的地方差在哪儿?怎么改进?
这个问题其实一直困扰着我们,主要的难点其实有两个。
首先,评分实际上是一个很模糊的感觉。虽然它有个定量的结果,但是90分、88分之间的差别到底有多少呢?人们对于这种数字的感知是有一个误差的冗余感的。但是当需要你说出来一篇文章好在哪儿、差在哪儿的时候,每个人的价值观和价值取向是不同的。这就造成这个产品和技术做出来的时候,不同人对它的效果做的评估是不同的。
第二点,我们当时的人工智能技术只能做很浅显的自然语言处理,除了理解字面意思之外,顶多还能再往下理解一层含义。而这些句子更深的内涵很少能被理解。要想给它一个合适的评语,我们就必须要准备评语模板库,用这种库来配合自然语言处理技术。
但是随着产品的发展,很多人不满足于看这些套路的东西,大家希望看到一些更真诚的评语,而不是简单的套路。因此这个产品和技术就得不到客户的认可,一直停滞不前,直到2022年,ChatGPT的推出。
大模型背后的秘密其实很简单
在2022年11月30日,美国Open AI公司发布了ChatGPT,到今天我们国家其实也推出了很多自主可控的大模型。我想现在很多人都在使用类似的产品,这种大模型技术确实在颠覆认知,在我们工作生活的各个方面都扮演了非常重要的角色。

到底什么是GPT?其实GPT很简单,用Open AI公司CEO萨姆·奥尔特曼的一句话来讲,它就是在预测下一个单词,predict next-token。

我这里给几个例子。比如问日本的首都是什么?我们让大家预测的是东京这个单词。中国的首都是什么?我们让大家预测的是北京这个单词。
如果我把日本和中国两个字盖住,仅仅问大家首都是什么的时候,不同国家的人的回答就是不同的了。预测和预测的准确率实际上依赖于我们前面到底提了什么样的问题,或者到底往前看了多少个单词。
如果我把中国这两个字放开再问大家,无论问哪个国家的人,他们都会异口同声地回答中国的首都是北京。这就是因为我们往前看的单词数量已经足够多了。
但是,当我们把这件事放到历史课本当中,再去问大家中国的首都是哪里,这个答案可能就不一定能这么填了。唐朝的时候中国的首都就应该填长安,马可波罗到中国的时候,中国的首都就应该填大都。
所以下一个单词到底怎么预测,完全取决于我们前面到底提供了什么样的上下文信息,也就是往前看了多久。这种往前看单词去预测下一个单词的技术就叫语言模型,它的本质就是这么简单。
大模型的全称就是大语言模型,而它所谓的「大」,我们能看到的是参数量大、数据量大,但实际上它「大」的本质,它的应用需求是可以往前看更长的文本。现在的大语言模型已经基本上可以吞吐到100万个单词左右的体量,这才是大语言模型。
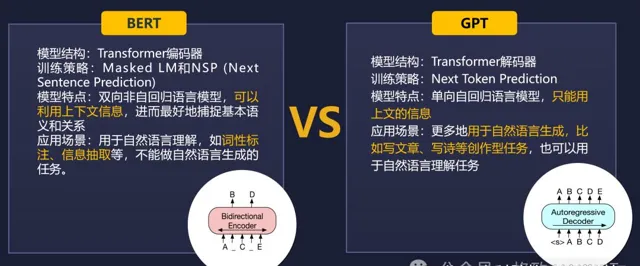
那没有GPT之前我们在干嘛呢?难道我们就不做这些任务了吗?没有GPT之前,我们用的模型叫BERT,这是一个小模型。
为什么那时候我们会用BERT模型而不用GPT呢?
原因很简单。第一,当GPT的参数量很小的时候,它的效果其实很一般,BERT模型完全可以碾压GPT,所以我们没有理由放弃一个效果更好的模型。
第二,GPT的参数变大的时候,它需要的算力也更大。说白了就是成本更多,普通的高校和科研院所就负担不起了。通常来讲,我们买几台服务器完全可以跑一个小模型,但是想去跑大模型就很困难了,更别提去做大模型的迭代和优化了。
BERT这个模型是看两边的信息猜中间,相当于是把句子里面的某个部分挖了填空。而GPT是只看前面的预测后面的,预测下一个单词。所以GPT有点像我们跟小朋友在家里玩接龙。你问他「床前明月」,他就会答「光」;「疑是地上」,他会答「霜」。甚至有的时候,随着小朋友年龄增长,你只需要提示两三个字,他就能把后面的句子接出来,这就是GPT。所以BERT用于做自然语言理解的任务更多一点,不能做这样生成的任务。
所以我们在没有GPT之前或者在GPT没有到达这样一个参数体量、没有出现智能涌现之前,更多地在用BERT这样的小模型。
但是,在Open AI公司2022年11月30日发布了ChatGPT,他们达到这样一个参数体量、出现智能涌现之后,我们体验了一周,分析了一周。两周之后,我们决定要开始这样的攻关,加强投入,买更多的服务器,收集更多的语料,训练中国人自己的大模型。

我们从第一行代码开始构建我们的星火大模型,当时定了一个框架叫做「1+N」
。「1」就是一个通用的认知智能大模型。这是一个「基座」,它学习了世界上所有的互联网知识,对于自然语言的理解不仅仅在文字层面,还有含义层面、语义层面,还有更深层次的内涵等等。这样它就能够理解我们想说的话了。
在这样一个通用大模型的基座之上,我们就可以构建很多垂直行业的小模型,比如教育的模型、办公的模型、汽车的模型还有交互以及医疗等等的模型。通过把这些领域的知识和语料拿进来,同时还可以用语料去做一些二次预训练,得到一个更大规模的模型。这样就可以在特定领域很好地应用。这就是我们做的星火大模型。
这样的大模型现在效果怎么样呢?我们可以给大家看几个例子。

这是一个图像理解的任务,简单来说就像小学做的看图说话。我们可以看到,它生成的效果既有宏观层面的也有微观层面的,既有前景的信息也有背景的信息。
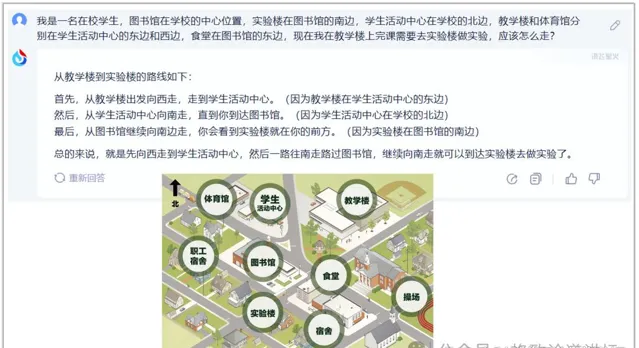
这个是描述一个地图让它去理解。它的空间方位感也不错。所以不仅有图有真相,更重要的是它还可以是一个活地图,能帮助我们去理解东西南北。
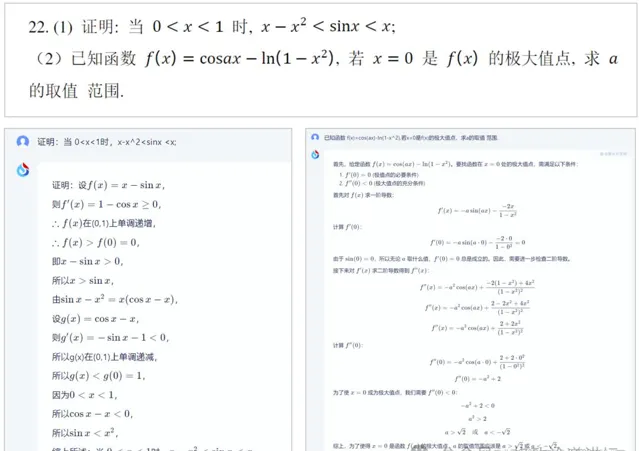
这个例子是我前两天测试的2023年安徽省高考最后一道压轴题,我们把它输入给大模型之后,大模型可以解答这道题,而且答案是完全正确的。看来现在让机器去考大学基本上是没有什么太大的难度了。
一切应用都值得重做一次
既然技术已经发展得足够好了,是不是就意味着它没有问题了呢?其实并不是,它还有很多缺陷仅仅靠大语言模型本身没有办法解决。今天我主要讲两个。

一个是新知识很难实时更新
。我们在2023年5月6日发布了星火大模型第一个版本,那时候我们问:刚刚过去的这个「五一」劳动节全国前三天发送的旅客数量有多少,星火和GPT都很难回答出来。
为什么?因为一个模型的训练通常需要一个月或者是几个月甚至更长的时间。随着参数量的扩大,这个模型的训练周期会更长。所以大家现在用的大模型实际上都是几个月之前训练好的,在它开始训练的时候到现在发生的这些事并没有进入它的语料体系里面,这就意味着它很难获得新知识。
第二个缺陷是,它会一本正经地胡说八道
,会对一些事实问题张冠李戴、胡乱编造。当我们问它唐朝的第三任皇帝是谁的时候,它会说是唐太宗李世民,但我们都知道是李治。
所以这些问题怎么去解决呢?我们得从根上找问题。
大家想想,人是怎么解决这个问题的?我们经常说知之为知之,不知为不知,是知也。你知道的可以回答,不知道的就不要不回答。
比如我现在问大家新中国是什么时候成立的,大家会异口同声说是1949年,因为这是知识。但如果我问你塞尔维亚共和国什么时候成立的,很多人会语塞,因为你不太了解这个冷门的知识。
这个时候人会怎么做?人会上互联网检索信息,统和一些信息之后给出答案。这不是知识,这叫逻辑,因为你在用逻辑整合信息。
在人的判断里,人是把知识和逻辑分开的。但是在大模型里,逻辑和知识是耦合在一块儿编在神经网络里面的。所以要解决张冠李戴和胡说八道的幻觉问题,实际上需要把知识和逻辑分开。
除此之外,我们还要做新知识的更新,我们不可能让大模型每一次都用最新的知识去自进化,所以我们需要接入互联网,让它自己从互联网上找到信息,对这些信息做整合。这就是我们讲的检索增强的技术。
所以,靠模型结构里边知识和逻辑的解耦,以及检索的增强,我们就可以让大模型克服知识难以更新以及张冠李戴的问题了。

有了这样的大模型技术,我们再回到当时困扰我的那个问题。现在我们把作文批改再做一遍,就可以做得很好,除了可以给学生提供基础的字、词、句、段、篇的修改,还可以做一些高级的批改以及给出提升建议,甚至可以给一些优化参考。
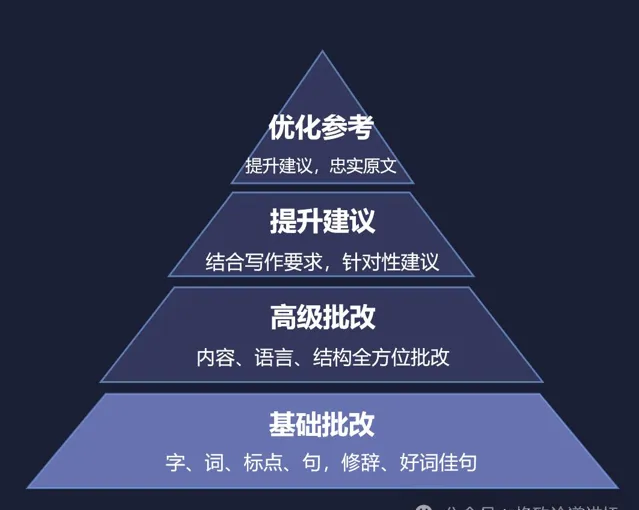
我想,这是大语言模型真正把我们以前想做的很多技术变得可以实现,也让我们的产品变得更加现实。可以简单来说,现在互联网上所有的产品,其实都可以用大语言模型重新再做一遍。
让AI成为科学家?
我们刚才讲的是面向大众的一些应用。那我们就在想,既然大模型可以完成高考,有上大学的水平,有没有可能让它做一些学术性的事情呢?
我们发现这件事是有可能的。因为大模型学互联网上的知识,实际上只能增长它的见识。但是如果让大模型去读科技文献、读论文、读专利、读标准,它就能增长学术见识。

于是,我们跟中国科学院文献情报中心合作,做了一个科技文献的大模型,把论文和专利信息「喂」给它,让它去学习。现在,我们就可以在网上让大模型去做成果调研了。
以前我们做调研的时候,需要看很多文章,然后自己去总结生成一篇综述。现在你只需要输入几个关键词,它就可以大致地给你在这个方向上写一篇综述文章出来,总体不超过两分钟。
我们以前做研究生的时候需要读大量论文。粗读一天能读5-10篇,精读一天顶多1-2篇。但在今天,如果把一篇很长的文献给大模型,大模型可以通过交互的方式,也就是通过问答的方式让它帮你快速地阅读,这就可以提升我们的科研效率。
我想,具备了这个能力的大模型实际上就已经有高年级本科生的水平,可以去从事相关领域的研究了。
做到这儿我们还不满足,于是就进一步想:如果它本科毕业之后想念研究生,应该去念一个什么样的专业?有没有可能变成硕士、博士甚至是科学家呢?我们不断地求索,希望它从一个科研助手变成真正的科学家同事。
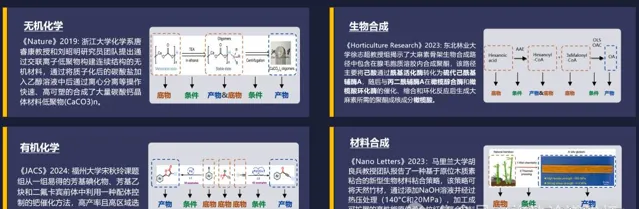
我们选了一个方向叫做合成科学。我们的衣食住行都离不开合成科学,它和化学、材料、生物、环境息息相关。丁奎岭院士有一句话:「合成科学是通往物质自由的希望之门。」
我们在高中都学过高锰酸钾分解制氧气这个实验。这个实验需要加热,加热之后变成水和氧气,还有一些其他产物。

但是,物质的合成其实很难。第一个难点是,合成是需要原料也就是底物的。那底物有多少种?光可能成为稳定材料的种类就有10180种,非常多。
第二个难点是条件。外在约束的条件有很多,温度、压强等等。而且这种变化既可以是离散的,也可以是连续的,所以它的取值有很多。当多个条件综合作用的时候,这种组合条件的可能性就更多了。
除此之外,大部分的反应网络不是一步完成的,而是多步完成的,这种合成路径也非常多。就好比我从合肥来到北京,既可以坐火车,也可以坐飞机;既可以直达,也可以中转。怎么去选择这样一个合成反应的网络路径呢?这也是非常重要的一件事。

让我们看看大模型能些到什么。大模型可以读取科技文献里的各种表格,这里面就蕴含了我们要用来做化学反应的底物的信息。接下来,等到我们想要合成一个新物质的时候,它就可以找到相似的合成产物,并且推荐一些可能的底物给他们。
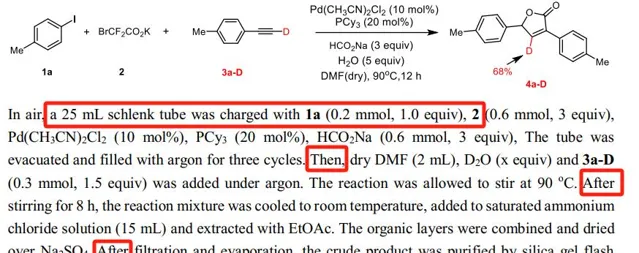
▲为实现氘标记实验,获得化学合成物的
反应合成路径(含底物以及实验条件)
文献里其实也包含了一些反应步骤。除了我们通常在文献里能看到的first、second、third(第一步、第二步、第三步)这样一些比较明显的英文之外,还可能包含then、after(然后、之后)这样一些隐式表达。于是大模型就可以知道化学反应到底应该怎么样一步一步进行的。
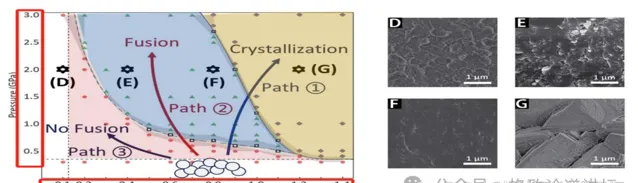
▲为实现无定形碳酸钙颗粒的融合获得
不同内部含水量(n)和外部压强(P)组合比
最有意思的其实是这张图,论文里面不仅仅有文字,还有图和表。这张图的横坐标是湿度,纵坐标是压强。科学家在做化学反应的时候,并不是所有的产物都需要,他们要的实际上只有中间蓝色的这块,而红色的和黄色的是残次品,是不需要的。
这就意味着,做实验时必须把湿度和压强控制在一个比较合适的范围里。而且这不是线性的控制,是曲线式的控制。合成这个材料的人需要去控制这些条件。
那我们就可以让读取图像的大模型去读这样的表和图,然后从里面把我们需要的条件抠出来,并且在条件和条件之间建立它们的联系和曲线函数,从而使科学家在未来需要去合成一个新物质的时候,把这样的条件贡献出来。
我想,能够推荐底物,也能够知道反应的条件,还能够给出合成的路径,再配上一些实验机器人,就可以让整个实验流程自动化。那实验室就不仅仅可以朝九晚五,还可以变成007。而且这不是我们人在「卷」,而是机器在「卷」。
如果这成为现实,那就可以释放很大的一部分科研精力,让科学家们去做一些更加天马行空的设想,攀登更高的科技制高点。
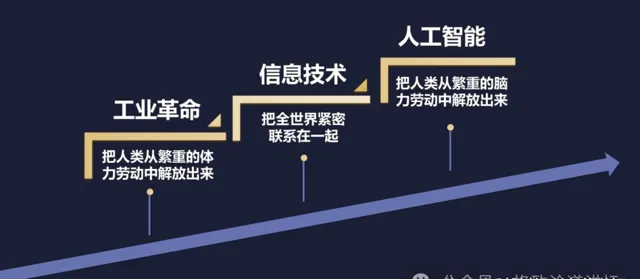
人工智能是站在我们新一代信息技术革命肩膀上的一个台阶。如果说工业革命是把人类从繁重的体力劳动当中解放出来,那么信息技术就是把全世界紧密地联系在一起,正如互联网把我们连成了「地球村」一样。而下一个台阶的智能革命,则是要把人类从繁重的脑力劳动当中解放出来。
今天,透过以大模型为代表的通用人工智能技术,我们已经能够看到人工智能的星星之火已开始燃起。

我们也特别希望大家都能够加入我们,一起让这样的星星之火服务于我们的经济社会和发展,形成促进我们国家经济增长的新的引擎,形成新质生产力,并形成燎原之势。
谢谢大家!











