從網頁上抓取數據,也就是常說的爬蟲功能,這個有什麽用處呢?就拿百度來講,大量的數據都是透過網路爬蟲的方式獲取,然後進行索引,排版,然後再透過搜尋入口提供給大家。一些網站或者套用會有我們需要的數據,而且數據是經常變動的,比如購物網站商品的價格,一些比價網透過定期抓取商城的價格,然後記錄下來,根據商品id形成價格的波動表,這樣再買商品時就能清楚地知道自己購買的是否劃算。說了這麽多,我們從基本的urllib模組來獲取一個網頁的html程式碼,並從中獲取想要的數據。

獲取氣象網站的連結數據,程式碼如下:
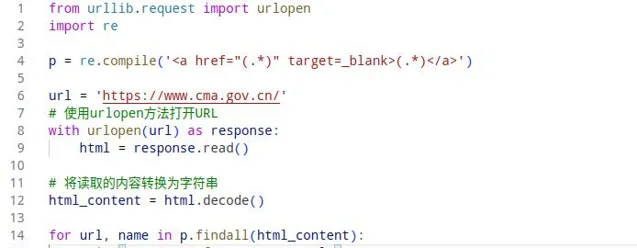
透過正規表式獲取連結數據
執行結果:

執行結果
正規表式的方式獲取文本比較靈活,但對於獲取網頁數據來講還是比較復雜了,畢竟網頁html是標準結構的,同時html也會存在復雜的結構,導致正規表式很難編寫與維護,這裏引入一個新模組Beautiful Soup,它是一個小巧而出色的模組,還可以用於解析在Web上可能遇到的不嚴謹且格式的HTML,上面的程式碼覆寫如下:
首先需要安裝模組:
pip install beautifulsoup4
程式碼:
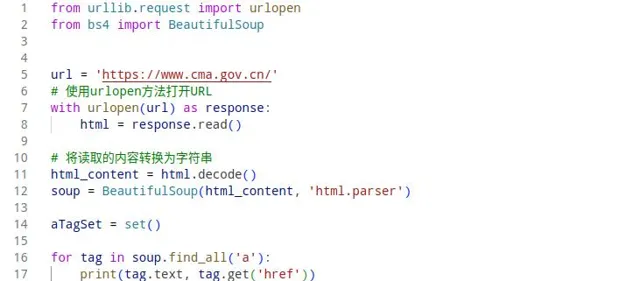
BeautifulSoup解析html
執行結果:

執行結果
Beautiful Soup常用方法:
find_all("標簽名") 返回標簽的列表,標簽主要有:連結a標簽,列表ul標簽,li標簽,模組的div標簽等。
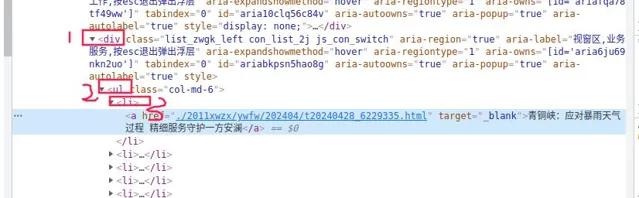
select("標簽的層級") 返回列表,比如select("div ul li"),html的結構如下圖:
以上就是網頁抓取的簡單介紹,了解更多精彩分享,敬請關註哦。











